
Key Take-aways #
- A relational database organizes data into tables of rows and columns and relates them to each other.
- A relational database links the tables with each other via primary and foreign keys, which minimizes redundant data and enables the efficient storage and query of data.
- SQL is the standard database language for retrieving, inserting, changing or deleting data in relational databases.
- The biggest advantage of relational databases is data integrity and transaction security, which is due to the ACID properties (atomicity, consistency, isolation, durability).
What is a relational database? #
A relational database is first and foremost a collection of structured information. It stores data in tables consisting of rows and columns and establishes relationships between the tables using keys. It uses SQL as standard for queries and changes, ensures high data integrity (ACID principles) and is perfect for managing structured data in large quantities.
How does a relational database work? #
Relational databases are based on a fundamental concept known as the relational model. The relational database model was developed in 1970 by the British mathematician Edgar F. Codd and is still the standard for databases today, despite the emergence of NoSQL solutions.
Let’s take a closer look at the design and structure of relational databases.
Tables and relationships #
Relational databases store information in tabular form. Each table consists of rows and columns, with each row representing a data record. Each column defines an attribute of the data records, so that as a rule each data record has a value for each attribute.
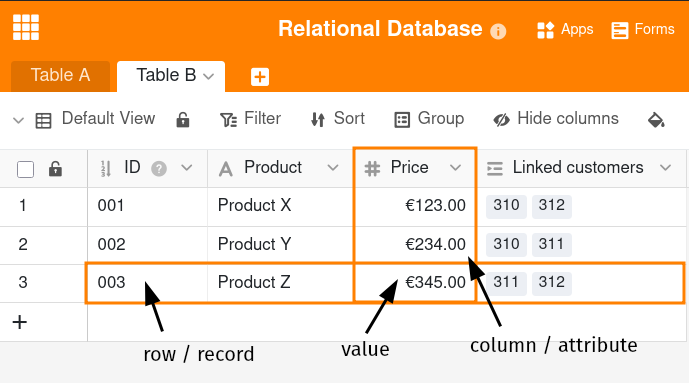
This clear structure of relational databases makes it possible to store data in different tables and link them through relationships. A relationship is a logical connection between two tables. Even a simplified relational database model consisting of table A and B allows different types of relationships:
- 1:1 relationship: Each data record from table A is assigned a maximum of one data record from table B and each data record from table B is assigned a maximum of one data record from table A.
- 1:n relationship: Each data record from table A can be linked to several data records from table B, but each data record from table B is assigned a maximum of one data record from table A.
- n:m relationship: Each data record from table A can be linked to several data records from table B and each data record from table B can be linked to several data records from table A.
Primary and foreign keys #
The relationships mentioned are created using primary and foreign keys. In a relational database, each row of a table has an identifier (ID) that uniquely identifies the data record. This row ID is referred to as the primary key of the database.
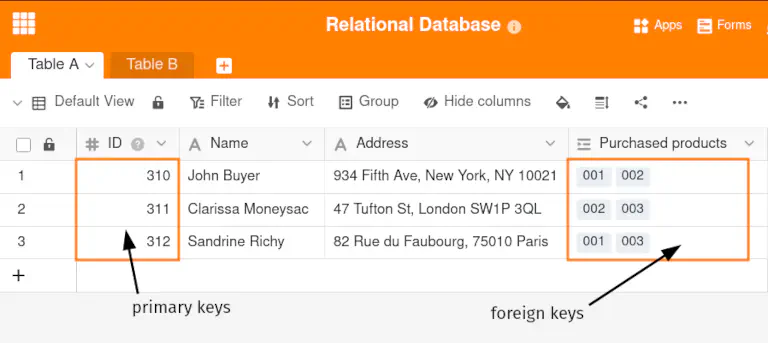
A foreign key in a database is the linked column, i.e. the attribute of a table that refers to a primary key in the same or another table.
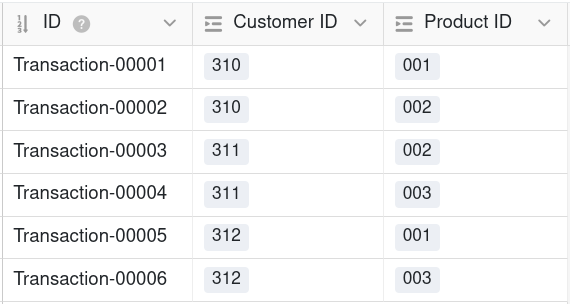
Accordingly, a relational database creates the link between two tables both in a 1:1 relationship and in a 1:n relationship by giving table B the primary keys of the data records from table A as foreign keys. For an n:m relationship, however, it requires another table that combines the primary keys of both linked data records as foreign keys in one row.
The ACID properties #
The following ACID properties ensure the data integrity and reliability of transactions in relational databases:
- Atomicity ensures that transactions are either complete or not executed at all, preventing data loss and incomplete transactions.
- Consistency guarantees that transactions adhere to all defined rules of the database so that the data is subsequently available correctly.
- Isolation ensures that parallel transactions do not influence each other, but remain invisible to others until they are completed.
- Durability means that the data is saved permanently after a transaction has been completed.
These principles not only reduce erroneous data, but also minimize the effects of system failures. By keeping the state of a relational database system consistent at all times, you can export, import and restore data quickly and easily.
Advantages of relational databases #
When databases were still in their infancy, each application stored data in its own hierarchical or networked structure. These data structures were inefficient, inflexible and difficult to maintain. Only the relational model solved this problem by introducing a tabular database logic that still enables efficient storage and retrieval of data today.
Another advantage of relational databases is their flexibility and adaptability to change. It is very easy to add, update or delete tables and data records without having to revise the entire database structure. This makes it easier to manage large amounts of data. In addition, tables offer an intuitive presentation of data and quick access to linked data records.
One of the biggest advantages of a relational database model is referential integrity. It ensures that each foreign key value exists in relation to the corresponding primary key. This prevents data inconsistencies and ensures that all relationships between the data records are correct.
Even if several users work with the data records at the same time, data consistency is maintained. In addition, a relational database model has advantages over non-relational databases because normalization reduces unwanted redundancies and anomalies.

SQL in relational databases #
The Structured Query Language (SQL) was developed specifically for relational databases and has established itself as a widely used database language. It was originally developed from a predecessor called SEQUEL (Structured English Query Language), which is why this pronunciation is still common today. It makes it possible to add, change or delete data in tables and to carry out complex database queries. SQL therefore plays a central role in the administration of relational databases.
Differences between relational and non-relational databases #
Non-relational databases, also known as NoSQL databases, are a collective term for all databases that are not based on a relational database model. These include in particular
- document-oriented databases
- object-oriented databases
- column-oriented databases
- Graph databases
- Key-value databases
As the names suggest, NoSQL solutions do not store data in tables, but as documents, objects, columns, graphs or key-value pairs, for example.
Horizontal vs. vertical scaling #
A non-relational database is designed to process unstructured data in large quantities (big data) and to scale horizontally, i.e. to distribute the load across different servers. In contrast, a relational database scales vertically on a single server. This means that the performance of the server (CPU, RAM) must be increased in order to process big data.

For this reason, relational databases usually have performance problems with data-intensive applications such as video streaming and cannot cope well when many changes occur simultaneously in large amounts of data. Nevertheless, a relational database is ideal for frequent but small data changes or large amounts of data with infrequent changes.
A non-relational database can handle many simultaneous accesses and changes even with huge amounts of data. However, NoSQL architectures usually offer little transaction security and data integrity, which makes them unusable for business-critical applications such as financial transactions.
Here is an overview of the differences between relational and non-relational databases:
| Aspect | relational database | non-relational database |
|---|---|---|
| Data organization | structured data in tables | unstructured data (e.g. documents) |
| Language | SQL | different (e.g. YAML) |
| Scaling | vertical | horizontal |
| Transaction security | high | low |
| Data integrity | strong | weak |
What you should look out for when selecting a database #
If you have to make a choice between different database types, you should consider certain factors when making your decision. Ask yourself the following questions, among others:
- Would you rather store structured data or unstructured data (e.g. documents)?
- What are your requirements in terms of data integrity and reliability of the database?
- How large are the expected data volumes and what scalability is required?
- Do you need agile data management because you want to make quick and flexible adjustments or several users need to access the data at the same time?
- How frequently will data changes occur and what conclusions can be drawn about the necessary performance of the database?
Use of relational databases in practice #
A relational database is the tool of choice if you want to ensure reliable, accurate and efficient data management. Therefore, relational databases are often used in practice for business-critical processes where maintaining data integrity is particularly important. For example, they are ideal for processing
- Financial transactions (e.g. payments)
- Inventory data in warehouse management
- Customer information in CRM systems
- Central master data
Due to their flexibility with simultaneous stringency in the data structure, relational databases are also suitable for many other use cases. They usually form the core of data warehouses .
Examples of relational database management systems (RDBMS) #
Classic databases #
Widely used relational database management systems (RDBMS) include MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server and IBM DB2. Each of these RDBMSs has its strengths and weaknesses. Which relational database system fits best depends largely on the specific requirements of your company.
No-code databases #
In recent years, no-code platforms such as SeaTable, which combine a visual user interface with a relational database, have also established themselves on the market. This allows you and your employees to create relational databases, applications and processes without any programming knowledge and use them without SQL queries.
SeaTable – the relational no-code database for agile data management #
SeaTable is an AI no-code platform that relies on a relational database model. It is designed to record structured data in tables, but can also handle unstructured data (e.g. images, documents) thanks to a special file management. The big difference to classic relational databases is the visual user interface, which enables anyone to evaluate and edit data and build databases, workflows and apps without SQL knowledge.
SeaTable offers high flexibility and helps you to customize, optimize and automate your processes. You can also use AI functions to make your data management even more efficient. You also have the freedom to choose whether you want to enjoy the convenience and scalability of the SeaTable Cloud or prefer to install SeaTable Server on-premises to retain full data sovereignty . Start with the free version and see for yourself!
Outlook: Future prospects for relational databases #
The future of relational databases will be strongly influenced by the question of how artificial intelligence can simplify the handling of data and automate routine tasks. It’s good that SeaTable has recognized the signs of the times and has already integrated AI automation into its relational database.
In addition, relational databases are increasingly moving to the cloud because this technology promises greater scalability, availability and performance when processing large volumes of data.
Last but not least, no-code databases will become more prominent, as they enable simple and fast data processing and queries without SQL knowledge, expand the user groups to include Citizen Developers and can adapt even more flexibly to the changing requirements of agile data management.
Frequently asked questions about relational databases #
What is a relational database?
What is SQL?
What are the differences between relational and non-relational databases?
What are the advantages of relational databases?
What are the ACID properties?