Table des matières
Lorsque vous connectez un agent IA à votre base SeaTable, vous lui donnez accès à des données professionnelles. Cet article explique comment contrôler cet accès, ce qu’il advient de vos données et quelles options vous avez pour adapter le niveau de sécurité à vos exigences.
Contrôler l’accès via le token API
L’accès d’un agent IA est entièrement contrôlé par le token API que vous créez dans SeaTable. Trois principes importants s’appliquent :
-
Un token, une base. Chaque token API est lié à exactement une base. L’agent ne peut pas accéder aux autres bases de votre compte, y compris celles qui ont été partagées avec vous. Si l’agent doit travailler avec plusieurs bases, créez un token distinct pour chacune.
-
Lecture ou lecture et écriture. Lors de la création du token, vous choisissez l’autorisation. Un token en lecture seule permet uniquement à l’agent d’interroger et d’analyser les données. Les modifications ne sont pas possibles — même si l’agent est invité à les effectuer. Un token en lecture-écriture permet en plus de créer, modifier et supprimer des entrées.
-
Révocable à tout moment. Vous pouvez supprimer un token API dans SeaTable à tout moment. L’accès de l’agent est immédiatement résilié.
Commencez avec un token en lecture seule. Cela vous permet de tester l’agent IA sans risque et de vous familiariser avec son fonctionnement. Lorsque vous êtes sûr de vouloir également utiliser des opérations d’écriture, créez un token en lecture-écriture.
Confirmation avant les modifications
Même avec un token en lecture-écriture, l’agent IA n’effectue pas de modifications de sa propre initiative. Les assistants IA comme Claude Desktop vous montrent exactement ce qui va se passer avant chaque action d’écriture — par exemple « Je souhaite ajouter 3 nouvelles lignes dans la table Contacts » — et attendent votre confirmation. Vous pouvez approuver ou rejeter chaque action individuellement.
Ce comportement n’est pas imposé par le serveur MCP, mais est une fonctionnalité de l’assistant IA. La plupart des clients compatibles MCP fonctionnent ainsi. Vérifiez si cette demande de confirmation est active dans votre assistant.
Quelles données sont transmises au fournisseur d’IA ?
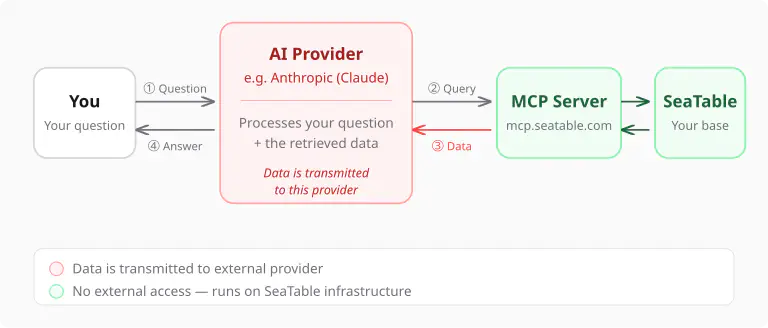
Lorsque l’agent IA répond à une question, le flux de données fonctionne comme suit :
- Votre question est envoyée au fournisseur d’IA (par ex. Anthropic pour Claude).
- L’agent IA décide de quelles données il a besoin et les interroge via le serveur MCP.
- Les résultats de la requête — c’est-à-dire les lignes et colonnes spécifiques de votre base — sont transmis au fournisseur d’IA pour que le modèle de langage puisse les évaluer.
- L’agent formule sa réponse et vous la renvoie.
Cela signifie : Les données que l’agent interroge sont transmises au fournisseur d’IA. C’est techniquement inévitable — un modèle de langage ne peut travailler qu’avec des données qu’il peut traiter.
Mes données sont-elles utilisées pour l’entraînement ?
Les grands fournisseurs d’IA distinguent clairement entre l’utilisation via leur interface web et l’utilisation via leur API. Pour l’accès API — et les connexions MCP passent par l’API — des règles plus strictes s’appliquent :
- Anthropic (Claude) : Les données traitées via l’API ne sont pas utilisées pour entraîner les modèles, selon les conditions d’utilisation d’Anthropic.
- OpenAI (ChatGPT/GPT-4) : OpenAI n’utilise pas non plus les données API pour l’entraînement des modèles par défaut.
Vérifiez les conditions d’utilisation actuelles de votre fournisseur d’IA, car elles peuvent évoluer.
Comment minimiser l’exposition des données ?
Même si les fournisseurs d’IA assurent que les données API ne sont pas utilisées à des fins d’entraînement, vous souhaiterez peut-être limiter la portée des données transmises. Plusieurs approches existent :
Base séparée pour l’agent. Au lieu de donner à l’agent l’accès à votre base principale, créez une base dédiée avec uniquement les données que l’agent doit voir. Cela sépare les données sensibles des données avec lesquelles l’agent travaille.
Utiliser un token en lecture seule. Si vous utilisez l’agent uniquement pour l’analyse, un token en lecture suffit. Cela garantit que l’agent ne peut modifier aucune donnée, même s’il y est invité.
Poser des questions ciblées. L’agent n’interroge que les données nécessaires pour votre question. Si vous demandez des informations sur un seul client, tous les clients ne sont pas transmis. Plus vos questions sont ciblées, moins de données circulent.
Contrôle maximal : auto-hébergement
Pour ceux qui traitent des données sensibles et ne souhaitent pas qu’elles soient transmises à des fournisseurs d’IA externes, SeaTable offre une option particulière : l’auto-hébergement avec un modèle de langage local.
Dans cette configuration, vous exploitez à la fois SeaTable et le serveur MCP sur votre propre infrastructure et les connectez à un modèle de langage exécuté localement (par exemple via Ollama ou LM Studio). Ainsi, vos données ne quittent jamais votre réseau.
Cette option s’adresse aux utilisateurs techniquement expérimentés et aux organisations ayant des exigences strictes en matière de protection des données. Les détails de configuration se trouvent dans la documentation technique sur GitHub .
Résumé
| Aspect | Détails |
|---|---|
| Portée de l’accès | Un token API = une base, pas d’accès aux autres bases ou au compte |
| Autorisations | Lecture ou lecture-écriture, révocable à tout moment |
| Confirmation | Les assistants IA demandent une approbation avant les actions d’écriture |
| Transmission des données | Les données interrogées sont transmises au fournisseur d’IA |
| Entraînement des modèles | Les données API ne sont pas utilisées pour l’entraînement selon les fournisseurs |
| Contrôle maximal | Auto-hébergement + modèle de langage local possible |