Оглавление
Когда вы подключаете ИИ-агента к своей базе SeaTable, вы предоставляете ему доступ к деловым данным. Эта статья объясняет, как контролировать этот доступ, что происходит с вашими данными и какие возможности у вас есть для настройки уровня безопасности в соответствии с вашими требованиями.
Управление доступом через API-токен
Доступ ИИ-агента полностью контролируется API-токеном, который вы создаёте в SeaTable. Действуют три важных принципа:
-
Один токен — одна база. Каждый API-токен привязан к одной конкретной базе. Агент не может получить доступ к другим базам в вашем аккаунте, включая базы, к которым вам предоставлен совместный доступ. Если агенту нужно работать с несколькими базами, создайте отдельный токен для каждой.
-
Чтение или чтение и запись. При создании токена вы выбираете разрешение. Токен на чтение позволяет агенту только запрашивать и анализировать данные. Изменения невозможны — даже если агента попросят их сделать. Токен на чтение и запись дополнительно позволяет создавать, редактировать и удалять записи.
-
Отзыв в любое время. Вы можете удалить API-токен в SeaTable в любой момент. Доступ агента будет немедленно прекращён.
Начните с токена на чтение. Это позволит вам без рисков опробовать ИИ-агента и познакомиться с его работой. Когда вы убедитесь, что хотите использовать и операции записи, создайте токен на чтение и запись.
Подтверждение перед изменениями
Даже с токеном на чтение и запись ИИ-агент не вносит изменения самостоятельно. ИИ-помощники, такие как Claude Desktop, показывают вам, что именно произойдёт, перед каждым действием записи — например «Я хотел бы добавить 3 новые строки в таблицу Контакты» — и ждут вашего подтверждения. Вы можете одобрить или отклонить каждое действие отдельно.
Такое поведение определяется не MCP-сервером, а является функцией ИИ-помощника. Большинство клиентов с поддержкой MCP работают именно так. Проверьте, активен ли этот запрос подтверждения в вашем помощнике.
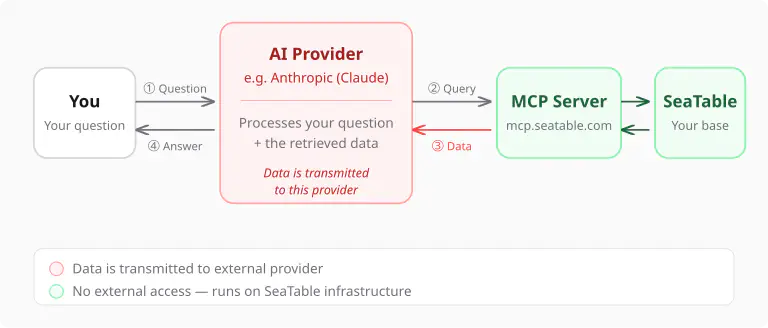
Какие данные передаются поставщику ИИ?
Когда ИИ-агент отвечает на вопрос, поток данных выглядит следующим образом:
- Ваш вопрос отправляется поставщику ИИ (напр. Anthropic для Claude).
- ИИ-агент решает, какие данные ему нужны, и запрашивает их через MCP-сервер.
- Результаты запроса — то есть конкретные строки и столбцы из вашей базы — передаются поставщику ИИ, чтобы языковая модель могла их обработать.
- Агент формулирует свой ответ и отправляет его вам.
Это означает: Данные, которые запрашивает агент, передаются поставщику ИИ. Это технически неизбежно — языковая модель может работать только с данными, которые она может обработать.
Используются ли мои данные для обучения?
Крупные поставщики ИИ чётко разграничивают использование через веб-интерфейс и использование через API. Для доступа через API — а MCP-соединения работают через API — действуют более строгие правила:
- Anthropic (Claude): Данные, обработанные через API, не используются для обучения моделей, согласно условиям использования Anthropic.
- OpenAI (ChatGPT/GPT-4): OpenAI также по умолчанию не использует данные API для обучения моделей.
Проверяйте актуальные условия использования вашего поставщика ИИ, так как они могут измениться.
Как минимизировать раскрытие данных?
Даже если поставщики ИИ гарантируют, что данные API не используются для обучения, вы можете захотеть ограничить объём передаваемых данных. Существует несколько подходов:
Отдельная база для агента. Вместо того чтобы давать агенту доступ к основной базе, создайте отдельную базу только с теми данными, которые агент должен видеть. Это отделит конфиденциальные данные от данных, с которыми работает агент.
Использование токена только на чтение. Если вы используете агента только для анализа, токена на чтение достаточно. Это гарантирует, что агент не сможет изменить никакие данные, даже если его об этом попросят.
Задавайте целевые вопросы. Агент запрашивает только те данные, которые нужны для вашего вопроса. Если вы спрашиваете об одном клиенте, не все клиенты передаются. Чем точнее ваши вопросы, тем меньше данных передаётся.
Максимальный контроль: самостоятельное размещение
Для тех, кто обрабатывает конфиденциальные данные и не хочет их передачи внешним поставщикам ИИ, SeaTable предлагает особую возможность: самостоятельное размещение с локальной языковой моделью.
В этой конфигурации вы запускаете и SeaTable, и MCP-сервер на собственной инфраструктуре и подключаете его к локально работающей языковой модели (например, через Ollama или LM Studio). Таким образом, ваши данные никогда не покидают вашу сеть.
Эта опция предназначена для технически опытных пользователей и организаций со строгими требованиями к защите данных. Подробности настройки можно найти в технической документации на GitHub .
Резюме
| Аспект | Подробности |
|---|---|
| Область доступа | Один API-токен = одна база, нет доступа к другим базам или аккаунту |
| Разрешения | Чтение или чтение и запись, отзыв в любое время |
| Подтверждение | ИИ-помощники запрашивают одобрение перед действиями записи |
| Передача данных | Запрошенные данные передаются поставщику ИИ |
| Обучение моделей | Данные API не используются для обучения по заявлениям поставщиков |
| Максимальный контроль | Самостоятельное размещение + локальная языковая модель возможны |