Inhaltsverzeichnis
Wenn Sie einen KI-Agenten mit Ihrer SeaTable-Base verbinden, geben Sie ihm Zugriff auf Geschäftsdaten. Dieser Artikel erklärt, wie Sie diesen Zugriff kontrollieren, was mit Ihren Daten passiert und welche Optionen Sie haben, um das Sicherheitsniveau an Ihre Anforderungen anzupassen.
Zugriff über API-Token steuern
Der Zugriff eines KI-Agenten wird vollständig über den API-Token gesteuert, den Sie in SeaTable erstellen. Dabei gelten drei wichtige Prinzipien:
-
Ein Token, eine Base. Jeder API-Token ist an genau eine Base gebunden. Der Agent kann nicht auf andere Bases in Ihrem Account zugreifen, auch nicht auf Bases, die für Sie freigegeben sind. Wenn der Agent mit mehreren Bases arbeiten soll, erstellen Sie für jede Base einen eigenen Token.
-
Lesen oder Lesen und Schreiben. Beim Erstellen des Tokens wählen Sie die Berechtigung. Ein Read-Token erlaubt dem Agenten nur, Daten abzufragen und zu analysieren. Änderungen sind damit nicht möglich — auch dann nicht, wenn der Agent dazu aufgefordert wird. Ein Read-Write-Token erlaubt zusätzlich das Anlegen, Ändern und Löschen von Einträgen.
-
Jederzeit widerrufbar. Sie können einen API-Token jederzeit in SeaTable löschen. Der Zugriff des Agenten wird damit sofort beendet.
Starten Sie mit einem Read-Token. So können Sie den KI-Agenten risikofrei ausprobieren und sich mit seiner Arbeitsweise vertraut machen. Wenn Sie sicher sind, dass Sie auch schreibende Operationen nutzen möchten, erstellen Sie einen Read-Write-Token.
Bestätigung vor Änderungen
Auch mit einem Read-Write-Token führt der KI-Agent Änderungen nicht eigenmächtig durch. KI-Assistenten wie Claude Desktop zeigen Ihnen vor jeder schreibenden Aktion an, was genau passieren wird — zum Beispiel “Ich möchte 3 neue Zeilen in der Tabelle Kontakte anlegen” — und warten auf Ihre Bestätigung. Sie können jede Aktion einzeln genehmigen oder ablehnen.
Dieses Verhalten ist nicht vom MCP Server vorgegeben, sondern eine Eigenschaft des KI-Assistenten. Die meisten MCP-fähigen Clients arbeiten so. Prüfen Sie bei Ihrem Assistenten, ob diese Sicherheitsabfrage aktiv ist.
Welche Daten werden an den KI-Anbieter übertragen?
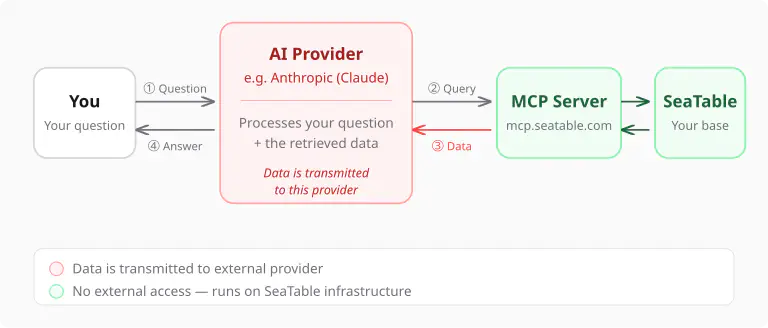
Wenn der KI-Agent eine Frage beantwortet, läuft der Datenfluss wie folgt:
- Ihre Frage wird an den KI-Anbieter gesendet (z.B. Anthropic bei Claude).
- Der KI-Agent entscheidet, welche Daten er braucht, und fragt sie über den MCP Server ab.
- Die Abfrageergebnisse — also die konkreten Zeilen und Spalten aus Ihrer Base — werden an den KI-Anbieter übertragen, damit das Sprachmodell sie auswerten kann.
- Der Agent formuliert seine Antwort und sendet sie an Sie zurück.
Das bedeutet: Die Daten, die der Agent abfragt, werden an den KI-Anbieter übertragen. Das ist technisch unvermeidbar — ein Sprachmodell kann nur mit Daten arbeiten, die es verarbeiten kann.
Werden meine Daten zum Training verwendet?
Die großen KI-Anbieter unterscheiden klar zwischen der Nutzung über ihre Weboberfläche und der Nutzung über ihre API. Für API-Zugriffe — und MCP-Verbindungen laufen über die API — gelten strengere Regeln:
- Anthropic (Claude): Daten, die über die API verarbeitet werden, werden laut Anthropics Nutzungsbedingungen nicht zum Trainieren von Modellen verwendet.
- OpenAI (ChatGPT/GPT-4): Auch OpenAI verwendet API-Daten standardmäßig nicht für Modelltraining.
Prüfen Sie die aktuellen Nutzungsbedingungen Ihres KI-Anbieters, da sich diese ändern können.
Wie kann ich die Datenexposition minimieren?
Auch wenn die KI-Anbieter zusichern, API-Daten nicht zu Trainingszwecken zu nutzen, möchten Sie vielleicht den Umfang der übertragenen Daten begrenzen. Dafür gibt es mehrere Ansätze:
Separate Base für den Agenten. Statt den Agenten auf Ihre Haupt-Base zugreifen zu lassen, erstellen Sie eine eigene Base mit den Daten, die der Agent sehen soll. So trennen Sie sensible Daten von den Daten, mit denen der Agent arbeitet.
Read-Only-Token verwenden. Wenn Sie den Agenten nur zur Analyse nutzen, reicht ein Lese-Token. So ist sichergestellt, dass der Agent keine Daten verändern kann, selbst wenn er dazu aufgefordert wird.
Gezielte Fragen stellen. Der Agent fragt nur die Daten ab, die er für Ihre Frage braucht. Wenn Sie nach einem einzelnen Kunden fragen, werden nicht alle Kunden übertragen. Je gezielter Ihre Fragen, desto weniger Daten fließen.
Maximale Kontrolle: Self-Hosting
Wer sensible Daten verarbeitet und nicht möchte, dass diese an externe KI-Anbieter übertragen werden, hat mit SeaTable eine besondere Option: Self-Hosting mit lokalem Sprachmodell.
In dieser Konfiguration betreiben Sie sowohl SeaTable als auch den MCP Server auf Ihrer eigenen Infrastruktur und verbinden ihn mit einem lokal laufenden Sprachmodell (zum Beispiel über Ollama oder LM Studio). So verlassen Ihre Daten zu keinem Zeitpunkt Ihr Netzwerk.
Diese Option richtet sich an technisch versierte Nutzer und Organisationen mit strengen Datenschutzanforderungen. Details zur Einrichtung finden Sie in der technischen Dokumentation auf GitHub .
Zusammenfassung
| Aspekt | Details |
|---|---|
| Zugriffsscope | Ein API-Token = eine Base, kein Zugriff auf andere Bases oder den Account |
| Berechtigungen | Read oder Read-Write, jederzeit widerrufbar |
| Bestätigung | KI-Assistenten fragen vor schreibenden Aktionen nach |
| Datenübertragung | Abgefragte Daten werden an den KI-Anbieter übertragen |
| Modelltraining | API-Daten werden laut Anbietern nicht zum Training verwendet |
| Maximale Kontrolle | Self-Hosting + lokales Sprachmodell möglich |