
Principais conclusões #
- Uma base de dados relacional organiza os dados em tabelas de linhas e colunas e relaciona-os entre si.
- Ela liga as tabelas entre si através de chaves primárias e estrangeiras, o que minimiza os dados redundantes e permite o armazenamento e a recuperação eficientes dos dados.
- A SQL é a linguagem de base de dados padrão para recuperar, inserir, alterar ou eliminar dados em bases de dados relacionais.
- A maior vantagem das bases de dados relacionais é a integridade dos dados e a segurança das transacções, o que se deve às propriedades ACID (atomicidade, consistência, isolamento, durabilidade).
O que é uma base de dados relacional? #
Uma base de dados relacional é, antes de mais, uma coleção de informações estruturadas. Armazena os dados em tabelas compostas por linhas e colunas e estabelece relações entre as tabelas utilizando chaves. Utiliza SQL como padrão para consultas e alterações, garante uma elevada integridade dos dados (princípios ACID) e é perfeita para gerir dados estruturados em grandes quantidades.
Como funciona uma base de dados relacional? #
As bases de dados relacionais baseiam-se num conceito fundamental conhecido como modelo relacional. O modelo de base de dados relacional foi desenvolvido em 1970 pelo matemático britânico Edgar F. Codd e continua a ser a norma para as bases de dados atualmente, apesar do aparecimento de soluções NoSQL.
Vamos analisar mais detalhadamente a conceção e a estrutura das bases de dados relacionais.
Tabelas e relações #
As bases de dados relacionais armazenam informações em forma de tabela. Cada tabela é composta por linhas e colunas, sendo que cada linha representa um registo de dados. Cada coluna define um atributo dos registos de dados, pelo que, regra geral, cada registo de dados tem um valor para cada atributo.
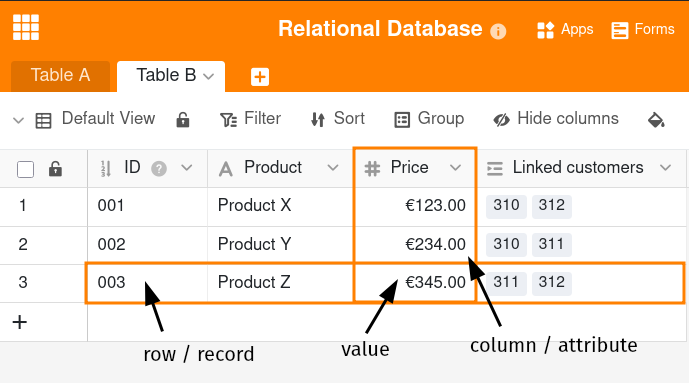
Esta estrutura clara das bases de dados relacionais permite armazenar dados em diferentes tabelas e ligá-los através de relações. Uma relação é uma ligação lógica entre duas tabelas. Mesmo um modelo simplificado de base de dados relacional constituído pelas tabelas A e B permite diferentes tipos de relações:
- Relação 1:1: A cada registo de dados da tabela A é atribuído um máximo de um registo de dados da tabela B e a cada registo de dados da tabela B é atribuído um máximo de um registo de dados da tabela A.
- Relação 1:n: Cada registo de dados da tabela A pode ser ligado a vários registos de dados da tabela B, mas a cada registo de dados da tabela B é atribuído um máximo de um registo de dados da tabela A.
- Relação n:m: Cada registo de dados da tabela A pode ser ligado a vários registos de dados da tabela B e cada registo de dados da tabela B pode ser ligado a vários registos de dados da tabela A.
Chaves primárias e estrangeiras #
As relações mencionadas são criadas utilizando chaves primárias e estrangeiras. Numa base de dados relacional, cada linha de uma tabela tem um identificador (ID) que identifica exclusivamente o registo de dados. Este identificador de linha é referido como a chave primária da base de dados.
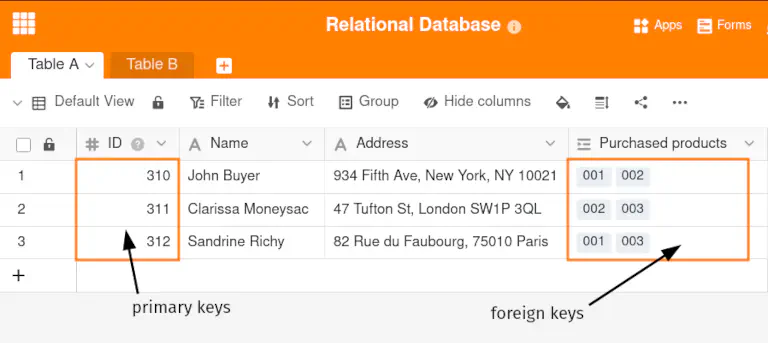
Uma chave estrangeira numa base de dados é a coluna ligada, ou seja, o atributo de uma tabela que se refere a uma chave primária na mesma ou noutra tabela.
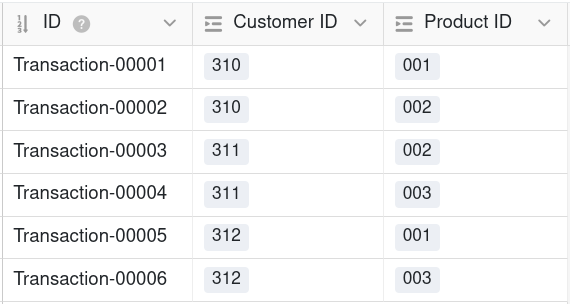
Assim, uma base de dados relacional cria a ligação entre duas tabelas, tanto numa relação 1:1 como numa relação 1:n, atribuindo à tabela B as chaves primárias dos registos de dados da tabela A como chaves estrangeiras. No entanto, para uma relação n:m, é necessária outra tabela que combine as chaves primárias de ambos os registos de dados ligados como chaves estrangeiras numa linha.
As propriedades ACID #
As seguintes propriedades ACID garantem a integridade dos dados e a fiabilidade das transacções em bases de dados relacionais:
- Atomicidade garante que as transacções ou são completas ou não são executadas de todo, evitando a perda de dados e transacções incompletas.
- Consistência garante que as transacções cumprem todas as regras definidas da base de dados, de modo a que os dados estejam subsequentemente disponíveis de forma correta.
- Isolamento garante que as transacções paralelas não se influenciam mutuamente, permanecendo invisíveis para os outros até serem concluídas.
- Durabilidade significa que os dados são guardados permanentemente após a conclusão de uma transação.
Estes princípios não só reduzem os dados erróneos, como também minimizam os efeitos das falhas do sistema. Ao assegurar que o estado de um sistema de base de dados relacional é consistente em todos os momentos, pode exportar, importar e restaurar dados rápida e facilmente.
Vantagens das bases de dados relacionais #
Quando as bases de dados ainda estavam a dar os primeiros passos, cada aplicação armazenava dados na sua própria estrutura hierárquica ou em rede. Estas estruturas de dados eram ineficientes, inflexíveis e difíceis de manter. Só o modelo relacional resolveu este problema, introduzindo uma lógica de base de dados tabular que ainda hoje permite armazenamento e recuperação eficientes de dados.
Outra vantagem das bases de dados relacionais é a sua flexibilidade e adaptabilidade à mudança. É muito fácil acrescentar, atualizar ou eliminar tabelas e registos de dados sem ter de rever toda a estrutura da base de dados. Isto facilita a gestão de grandes quantidades de dados. Além disso, as tabelas oferecem uma visualização intuitiva dos dados e um acesso rápido aos registos de dados ligados.
Uma das maiores vantagens de um modelo de base de dados relacional é a integridade referencial. Esta garante que cada valor de chave externa existe em relação à chave primária correspondente. Isto evita inconsistências de dados e garante que todas as relações entre os registos de dados estão corretas.
Mesmo que vários utilizadores estejam a trabalhar com os registos de dados ao mesmo tempo, a consistência dos dados é mantida. Além disso, um modelo de base de dados relacional tem vantagens sobre as bases de dados não relacionais porque a normalização reduz as redundâncias e anomalias indesejadas.

SQL em bases de dados relacionais #
A Structured Query Language (SQL) foi desenvolvida especificamente para bases de dados relacionais e estabeleceu-se como uma linguagem de base de dados amplamente utilizada. Foi originalmente desenvolvida a partir de uma antecessora chamada SEQUEL (Structured English Query Language), razão pela qual esta pronúncia ainda é comum atualmente. Permite acrescentar, alterar ou apagar dados em tabelas e efetuar consultas complexas à base de dados. A SQL desempenha, portanto, um papel central na administração de bases de dados relacionais.
Diferenças entre bases de dados relacionais e não relacionais #
As bases de dados não relacionais, também conhecidas como bases de dados NoSQL, são um termo coletivo para todas as bases de dados que não se baseiam num modelo de base de dados relacional. Estas incluem, nomeadamente
- bases de dados orientadas para documentos
- bases de dados orientadas para objectos
- bases de dados orientadas para as colunas
- Bases de dados de grafos
- Bases de dados de valores chave
Tal como os nomes sugerem, as soluções NoSQL não armazenam dados em tabelas, mas sim, por exemplo, como documentos, objectos, colunas, gráficos ou pares chave-valor.
Escalonamento horizontal vs. vertical #
Uma base de dados não relacional foi concebida para processar dados não estruturados em grandes quantidades (big data) e para escalar horizontalmente, ou seja, para distribuir a carga por diferentes servidores. Em contrapartida, uma base de dados relacional é dimensionada verticalmente num único servidor. Isto significa que o desempenho do servidor (CPU, RAM) deve ser aumentado para processar grandes volumes de dados.

É por esta razão que as bases de dados relacionais têm normalmente problemas de desempenho com aplicações de grande volume de dados, como o streaming de vídeo, e não conseguem lidar bem com a ocorrência simultânea de muitas alterações em grandes quantidades de dados. No entanto, uma base de dados relacional é ideal para alterações de dados frequentes mas pequenas ou grandes quantidades de dados com alterações pouco frequentes.
Uma base de dados não relacional pode lidar com muitos acessos e alterações simultâneos, mesmo com grandes quantidades de dados. No entanto, as arquitecturas NoSQL oferecem normalmente pouca segurança nas transacções e integridade dos dados, o que as torna inutilizáveis para aplicações críticas para o negócio, como as transacções financeiras.
Eis um resumo das diferenças entre bases de dados relacionais e não relacionais:
| aspeto | base de dados relacional | base de dados não relacional |
|---|---|---|
| Organização dos dados | estruturados em tabelas | não estruturados |
| Linguagem | SQL | diferente (por exemplo, YAML) |
| Escalonamento | vertical | horizontal |
| Segurança das transacções | alta | baixa |
| Integridade dos dados | forte | fraca |
O que deve ter em atenção ao selecionar uma base de dados #
Se tiver de fazer uma escolha entre diferentes tipos de bases de dados, deve ter em conta determinados factores ao tomar a sua decisão. Faça a si próprio as seguintes perguntas, entre outras:
- Prefere armazenar dados estruturados ou dados não estruturados (por exemplo, documentos)?
- Quais são os seus requisitos em termos de integridade dos dados e fiabilidade da base de dados?
- Qual a dimensão dos volumes de dados previstos e qual a escalabilidade necessária?
- Necessita de uma gestão de dados ágil porque pretende fazer ajustes de forma rápida e flexível ou porque vários utilizadores precisam de aceder aos dados ao mesmo tempo?
- Com que frequência ocorrerão alterações nos dados e que conclusões podem ser tiradas sobre o desempenho necessário da base de dados?
Utilização de bases de dados relacionais na prática #
Uma base de dados relacional é a ferramenta de eleição se quiser garantir uma gestão de dados fiável, exacta e eficiente. Por conseguinte, as bases de dados relacionais são frequentemente utilizadas na prática para processos críticos em que a manutenção da integridade dos dados é particularmente importante. Por exemplo, são ideais para o processamento de
- Transacções financeiras (por exemplo, pagamentos)
- Dados de inventário em gestão de armazéns
- Informações sobre clientes em sistemas CRM
- Dados principais centrais
Devido à sua flexibilidade com rigor simultâneo na estrutura de dados, as bases de dados relacionais também são adequadas para muitas outras aplicações. Constituem normalmente a peça central dos armazéns de dados .
Exemplos de sistemas de gestão de bases de dados relacionais (SGBDR) #
Bases de dados clássicas #
Os sistemas de gestão de bases de dados relacionais (SGBDR) muito utilizados incluem MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server e IBM DB2. Cada um destes RDBMS tem os seus pontos fortes e fracos. O sistema de base de dados relacional mais adequado depende muito dos requisitos específicos da sua empresa.
Bases de dados sem código #
Nos últimos anos, plataformas no-code como SeaTable também se estabeleceram no mercado, combinando uma interface de utilizador visual com uma base de dados relacional. Isto permite-lhe a si e aos seus empregados criar bases de dados relacionais, aplicações e processos sem qualquer conhecimento de programação e utilizá-los sem consultas SQL.
SeaTable – a base de dados relacional sem código para uma gestão de dados ágil #
SeaTable é uma plataforma no-code de IA que assenta num modelo de base de dados relacional. Foi concebida para registar dados estruturados em tabelas, mas também pode tratar dados não estruturados (por exemplo, imagens, documentos) graças a uma gestão de ficheiros especial. A grande diferença em relação às bases de dados relacionais clássicas é a interface visual do utilizador, que permite a qualquer pessoa analisar e editar dados e criar bases de dados, fluxos de trabalho e aplicações sem conhecimentos de SQL.
SeaTable oferece alta flexibilidade e ajuda-o a personalizar, otimizar e automatizar os seus processos. Pode também utilizar funções de IA para tornar a sua gestão de dados ainda mais eficiente. Também tem a liberdade de escolher se pretende usufruir da conveniência e da escalabilidade do SeaTable Cloud ou se prefere instalar o SeaTable Server no local para manter a soberania dos dados . Comece com a versão gratuita e veja por si próprio!
Perspectivas futuras para as bases de dados relacionais #
O futuro das bases de dados relacionais será fortemente caracterizado pela questão de como a inteligência artificial pode simplificar o tratamento dos dados e automatizar as tarefas de rotina. É bom que SeaTable tenha reconhecido os sinais dos tempos e já tenha integrado a automatização da IA na sua base de dados relacional.
Além disso, as bases de dados relacionais estão a migrar cada vez mais para a nuvem porque esta tecnologia promete maior escalabilidade, disponibilidade e desempenho no processamento de grandes volumes de dados.
Por último, mas não menos importante, as bases de dados no-code tornar-se-ão mais proeminentes, uma vez que permitem o processamento e a consulta simples e rápidos de dados sem conhecimentos de SQL, expandem a base de utilizadores para incluir os Citizen Developers e podem adaptar-se de forma ainda mais flexível aos requisitos em mudança da gestão ágil de dados.
Perguntas frequentes sobre bases de dados relacionais #
O que é uma base de dados relacional?
O que é SQL?
Quais são as diferenças entre bases de dados relacionais e não relacionais?
Quais são as vantagens das bases de dados relacionais?
Quais são as propriedades ACID?