
¿Qué es un almacén de datos? #
Un almacén de datos (también abreviado como DWH) es un sistema de almacenamiento centralizado que reúne grandes cantidades de datos procedentes de distintas fuentes, los estructura y los prepara para su análisis. Al almacenar y visualizar la historia de los datos, se pueden identificar patrones, tendencias y correlaciones a lo largo del tiempo. Por eso, la inteligencia empresarial también desempeña un papel importante en los almacenes de datos.
Las funciones de análisis permiten extraer de los datos información valiosa sobre distintos ámbitos empresariales para mejorar la toma de decisiones. Si incorpora todos los datos de su empresa a su almacén de datos, puede incluso describirse como una única fuente de verdad, es decir, una base de datos completa y fiable.
Las ventajas de un almacén de datos #
- Facilitar la toma de decisiones: Con la ayuda de una base de datos sólida, podrá tomar decisiones con conocimiento de causa.
- Mejorar la calidad de los datos: Un almacén de datos limpia, consolida y normaliza grandes cantidades de datos para hacerlos utilizables.
- Visualizar correlaciones: En un sistema de almacén de datos, puede crear análisis, informes y presentaciones en un abrir y cerrar de ojos.
- Reconocer la evolución: En el almacén de datos se recopilan datos históricos de evolución a largo plazo de los que se pueden extraer patrones, tendencias y previsiones.
Las 4 características principales de los almacenes de datos #
El informático estadounidense Bill Inmon, considerado el “padre del almacén de datos”, define cuatro características de los almacenes de datos.
- Orientación temática: En primer lugar, se seleccionan los datos y cifras clave de un tema o área de negocio específicos (por ejemplo, ventas, finanzas, RRHH) para incluirlos en el DWH. ¿Qué información se necesita para los análisis posteriores y la toma de decisiones?
- Integrado: Un almacén de datos centraliza, normaliza y depura los datos procedentes de diversas fuentes y los almacena de forma estructurada. Esto garantiza un alto nivel de coherencia de los datos.
- Orientado al tiempo: Los datos históricos, que permiten analizar los cambios a lo largo del tiempo, son el núcleo del data warehousing. El almacenamiento de datos a largo plazo es necesario para poder analizar la evolución a lo largo del tiempo.
- No volátil: Una vez que los datos se han almacenado en el almacén de datos, no se deben modificar ni borrar, ya que de lo contrario se falsearía el historial. Por eso es importante que los datos no sean volátiles, sino estables.
Historia y futuro del almacén de datos #
Los primeros almacenes de datos aparecieron en el mercado a finales de los años ochenta. En aquella época, estaban destinados a suministrar datos a los sistemas de apoyo a la toma de decisiones y a los sistemas de información de gestión existentes.
-
Los sistemas de apoyo a la toma de decisiones (DSS) fueron las primeras soluciones de software que permitían modelar y simular datos para apoyar la toma de decisiones.
-
Los sistemas de información de gestión (SIG) se diseñaron para simplificar la preparación manual de datos y la creación de análisis gráficos para la alta dirección.
Sin embargo, los almacenes de datos de la época tenían que hacer frente a una enorme redundancia, ya que muchas empresas disponían de varios DSS y SIF para distintas áreas de negocio. Aunque los sistemas utilizaban en su mayoría los mismos datos, éstos se almacenaban a menudo por separado para cada entorno. Sin embargo, con el auge de las plataformas de inteligencia empresarial, el almacén de datos evolucionó hasta convertirse en un repositorio de información más eficiente con amplias capacidades analíticas para las distintas unidades de negocio.

Hoy en día, la IA, el aprendizaje automático y la automatización están abriendo posibilidades completamente nuevas para mejorar el rendimiento de los almacenes de datos. Este desarrollo conduce en última instancia a almacenes de datos autónomos que son completamente autogestionables y ya no requieren administración humana. Esto puede aliviar la carga del departamento de TI de su empresa y liberar tiempo para obtener aún más información de sus datos. Al mismo tiempo, puede reducir costes con un almacén de datos moderno y diseñar arquitecturas de almacén de datos optimizadas para los requisitos de diferentes usuarios y áreas especializadas.
Cómo se estructura un almacén de datos #
La forma exacta de configurar su sistema de almacén de datos depende de los requisitos específicos del almacén de datos de su empresa, que deberá definir en primer lugar. Sin embargo, todas las arquitecturas de almacén de datos comparten un diseño básico: los datos en bruto se almacenan temporalmente en un repositorio que se alimenta, por un lado, de fuentes de datos y, por otro, escribe los datos estructurados en una base de datos relacional. Al final, los usuarios acceden a los datos depurados a través de herramientas de BI para su análisis, visualización y elaboración de informes.
Componentes clave del almacenamiento de datos #
Un concepto típico de almacén de datos puede dividirse en los siguientes niveles:
- Las fuentes de datos internas, por ejemplo, los sistemas ERP y CRM, o las fuentes de datos externas, como los dispositivos IoT o las plataformas de medios sociales, proporcionan datos en bruto.
- Los datos brutos se almacenan temporalmente y se transforman en una zona de preparación. En el proceso ETL, el almacén de datos transforma los datos para su almacenamiento estructurado.
- el núcleo del almacén de datos suele ser una base de datos relacional, que almacena y gestiona los datos estructurados y depurados.
- un almacén de datos suele dividirse en varios marcos de datos. Éstos se centran en áreas especializadas o departamentos concretos (por ejemplo, ventas, marketing o finanzas).
- la extracción de datos, el análisis estadístico de datos, la visualización gráfica y la elaboración de informes se llevan a cabo con herramientas de BI como Tableau, Microsoft Power BI o Google Looker.
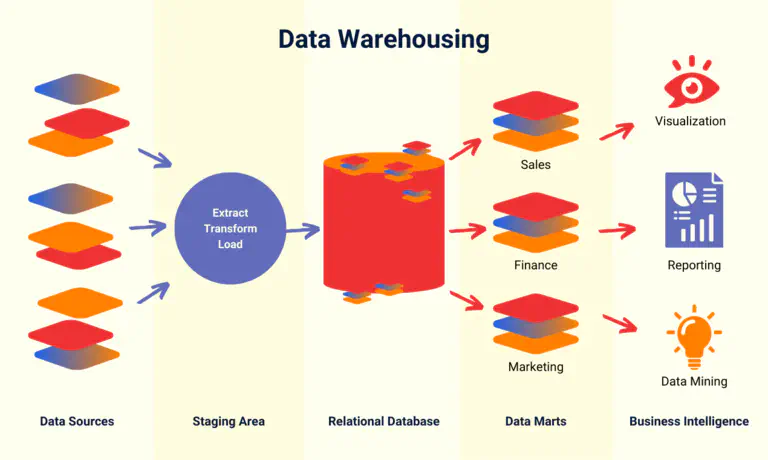
Proceso ETL para una gestión eficaz del almacén de datos #
Un almacén de datos utiliza los llamados procesos ETL para recopilar datos de diversas fuentes, transformarlos y cargarlos en la base de datos central. La abreviatura significa Extraer, Transformar, Cargar. El proceso ETL se desarrolla en tres pasos en la zona de preparación:
- La extracción: El almacén de datos recopila los datos deseados de diversas fuentes. Para que esto funcione, normalmente hay que conectar otros sistemas al sistema de almacén de datos a través de una API.
- la transformación: Se trata de limpiar, enriquecer y formatear los datos de manera estandarizada. Por ejemplo, el almacén de datos elimina duplicados, añade valores que faltan y adapta los tipos de datos.
- la carga: Por último, los datos depurados se transfieren a la base de datos central.
Ejemplo de proceso de un almacén de datos #
Las explicaciones anteriores eran bastante técnicas. He aquí otro ejemplo ilustrativo para mostrarle cómo funciona un proceso de almacén de datos.
Supongamos que dirige una tienda online y desea analizar los datos de ventas, tráfico y clientes. En primer lugar, debe considerar qué fuentes de datos deben incluirse en su almacén de datos y a qué sistemas debe acceder. En este caso, podría tratarse del historial de pedidos de Shopify, el tráfico web de Google Analytics y los datos de CRM de Pipedrive. Estos datos se limpian, armonizan y almacenan en el almacén de datos. Ahora puede evaluar estadísticamente todas las cifras de ventas y accesos, realizar análisis de clientes y sacar conclusiones para su estrategia de ventas y la mejora de su tienda online.

Diferencias entre un almacén de datos y una base de datos #
Un almacén de datos y una base de datos son dos sistemas de gestión de datos diferentes. Mientras que una base de datos suele centrarse en el almacenamiento de datos, el sistema de almacén de datos traza un proceso más largo, desde la adquisición de datos hasta su análisis, pasando por su integración y preparación. No obstante, los almacenes de datos también almacenan enormes cantidades de datos en una base de datos central, que es el corazón de toda solución DWH. A su vez, un almacén de datos sirve de base para los análisis y la elaboración de informes en toda la empresa.
| Almacén de datos | Base de datos |
|---|
| Propósito / Enfoque Análisis e Informes Almacenamiento de Datos | Alcance | Generalmente en toda la empresa | Variable |
¿Cuál es la diferencia entre un almacén de datos y un lago de datos? #
Un lago de datos es una especie de cuenca de recogida de todos los datos brutos de una organización. Puede tratarse tanto de datos estructurados procedentes de bases de datos relacionales como de datos no estructurados (por ejemplo, correos electrónicos, documentos PDF y archivos de imagen). Sin embargo, a diferencia de un almacén de datos, un lago de datos almacena los datos sin ajustar hasta que se desea prepararlos para su análisis o visualización según sea necesario. Puede imaginarse literalmente un data lake como un lago de datos en el que los datos de distintas fuentes fluyen juntos y descansan inicialmente sin procesar. Por tanto, los lagos de datos como Amazon S3, Microsoft Azure Data Lake o Google Cloud Storage permiten almacenar grandes cantidades de datos de forma rápida y flexible.

Las dos tecnologías básicas de almacén de datos #
Existen varias soluciones de almacén de datos en el mercado, que básicamente pueden clasificarse en nube u on-premises. Originalmente, los almacenes de datos sólo se ofrecían en servidores locales. Incluso hoy en día, estos almacenes de datos locales pueden tener ciertas ventajas en términos de seguridad y soberanía de los datos. Sin embargo, la administración de estos sistemas puede llevar mucho tiempo en el caso de arquitecturas complejas de almacenes de datos.
Ventajas del “almacén de datos en la nube” #
Un almacén de datos en la nube tiene, entre otras, las siguientes ventajas:
- Elasticidad y escalabilidad: Al disponer de un almacén de datos en la nube alojado en un centro de datos, tiene a su disposición una potencia de cálculo y un espacio de almacenamiento casi ilimitados. Dependiendo de la cantidad de datos, puede ampliar o reducir de forma flexible las capacidades utilizadas, es decir, aumentar o reducir la escala.
- Menores costes de explotación: Con DWH en la nube, no tiene que invertir en su infraestructura, contratar personal adicional y solo paga por la cantidad de recursos que realmente necesita (principio de pago por uso).
- Despliegue rápido: Puede crear un almacén de datos en la nube en poco tiempo gracias a los procesos ya preparados y personalizarlo según sus necesidades, mientras que una configuración en las instalaciones puede llevar varios meses e implica mucho trabajo de desarrollo.
- Datos en tiempo real: Las tecnologías DWH en memoria permiten procesar los datos a una velocidad vertiginosa. Basándose en datos en tiempo real, puede reconocer y analizar inmediatamente los cambios repentinos.
A continuación encontrará un resumen de las diferencias entre la nube y las instalaciones.
| En la nube | En las instalaciones** | En las instalaciones | |||
|---|---|---|---|---|---|
| Entrega | Instalación posible en cualquier lugar del mundo en poco tiempo | La instalación del hardware in situ puede llevar varias semanas | En la nube | En las instalaciones de la empresa | |
| Costes | Principio de “pago por uso”, sin costes adicionales de infraestructura y personal | Elevados costes de adquisición y funcionamiento de infraestructura y personal | Escalabilidad** | Posibilidad de instalación en cualquier lugar del mundo en poco tiempo | |
| Escalabilidad | Escalabilidad flexible, automática y sin límites | Planificación manual de la capacidad con límites claros | Seguridad | ||
| seguridad | alta codificación, copias de seguridad automáticas | control total y soberanía de datos, seguridad dependiente de sus procesos de TI |
| Actualización en tiempo real: muy rápida gracias a la tecnología en memoria. | Usabilidad** | a menudo fácil de usar gracias a los elementos prefabricados, sin dependencia de TI | a menudo complejo, los expertos en TI tienen que conectar las fuentes de datos y administrar el DWH |
SeaTable - el almacén de datos flexible, sencillo y rentable #
SeaTable es una plataforma sin código que ofrece la ventaja sobre otras bases de datos relacionales de que los usuarios pueden trabajar en una intuitiva interfaz gráfica de usuario sin SQL ni otros conocimientos informáticos. Con la ayuda de diversas vistas, plugins y estadísticas, puede preparar y visualizar fácilmente los datos de la forma que desee. Así le resultará más fácil realizar análisis precisos y tomar decisiones fundamentadas sin quebraderos de cabeza.
Los datos de innumerables fuentes pueden fluir hacia SeaTable a través de integraciones con Zapier, Make o n8n y la API de SeaTable. Para que SeaTable pueda guardar todos los datos de forma estructurada, seleccione de antemano los tipos de datos deseados . Gracias al principio modular de fácil uso, esto es tan sencillo como utilizar el Constructor de aplicaciones integrado para crear sus propias aplicaciones . SeaTable también permite la colaboración en equipo y actualiza los datos en tiempo real - los cambios son inmediatamente visibles para todos los usuarios y están totalmente documentados en el historial de versiones.
Además, puede elegir si desea operar su almacén de datos on-premises o en la nube . Benefíciese de la escalabilidad y comodidad de SeaTable Cloud o aloje SeaTable Server en sus propios servidores con total control y soberanía de los datos. Comience con la versión básica gratuita, que puede actualizar a una suscripción Plus o Enterprise en cualquier momento en cuanto necesite más funciones o espacio de almacenamiento.
Regístrese gratis y experimente lo fácil que puede ser el almacenamiento de datos.
Preguntas frecuentes sobre el almacenamiento de datos #
¿Qué es un almacén de datos?
¿Qué es un lago de datos?
¿Qué es un data mart?
¿Qué significa ETL?
TAGS: