
Key Take-aways #
- Eine relationale Datenbank organisiert Daten in Tabellen aus Zeilen und Spalten und setzt diese miteinander in Beziehung.
- Dabei verknüpft eine relationale Datenbank über Primär- und Fremdschlüssel die Tabellen miteinander, was redundante Daten minimiert und das effiziente Speichern und Abrufen der Daten ermöglicht.
- SQL ist die Standard-Datenbanksprache, um Daten in relationalen Datenbanken abzurufen, einzufügen, zu verändern oder zu löschen.
- Der größte Vorteil relationaler Datenbanken besteht in der Datenintegrität und Transaktionssicherheit, was den ACID-Eigenschaften (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) zu verdanken ist.
Was ist eine relationale Datenbank? #
Eine relationale Datenbank ist zunächst eine Sammlung strukturierter Informationen. Sie speichert Daten in Tabellen aus Zeilen und Spalten und stellt mithilfe von Schlüsseln Beziehungen zwischen den Tabellen her. Sie nutzt standardmäßig SQL für Abfragen und Änderungen, gewährleistet hohe Datenintegrität (ACID-Prinzipien) und eignet sich perfekt, um strukturierte Daten in großen Mengen zu verwalten.
Wie funktioniert eine relationale Datenbank? #
Relationale Datenbanken beruhen auf einem grundlegenden Konzept, das man als relationales Modell bezeichnet. Das relationale Datenbankmodell wurde 1970 vom britischen Mathematiker Edgar F. Codd entwickelt und ist trotz des Aufkommens von NoSQL-Lösungen bis heute der Standard für Datenbanken.
Sehen wir uns nun den Aufbau und die Struktur relationaler Datenbanken genauer an.
Tabellen und Beziehungen #
Relationale Datenbanken speichern Informationen in tabellarischer Form. Jede Tabelle besteht aus Zeilen und Spalten, wobei jede Zeile einen Datensatz darstellt. Jede Spalte definiert ein Attribut der Datensätze, sodass in der Regel jeder Datensatz über einen Wert für jedes Attribut verfügt.
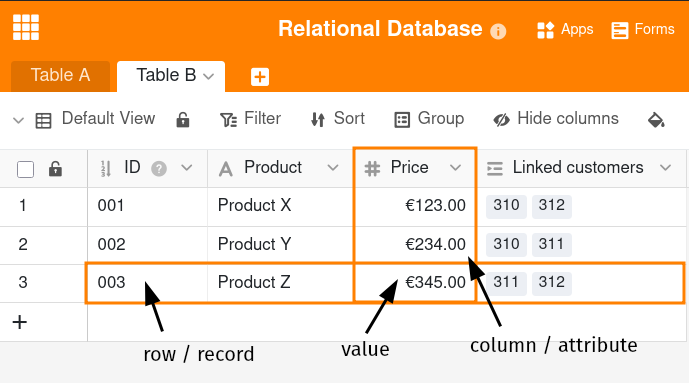
Dieser klare Aufbau relationaler Datenbanken ermöglicht es, Daten in verschiedenen Tabellen zu speichern und durch Beziehungen zu verknüpfen. Bei einer Beziehung handelt es sich um eine logische Verbindung zwischen zwei Tabellen. Bereits ein vereinfachtes relationales Datenbankmodell aus Tabelle A und B lässt verschiedene Arten von Beziehungen zu:
- 1:1-Beziehung: Jedem Datensatz aus Tabelle A ist maximal ein Datensatz aus Tabelle B zugeordnet und jedem Datensatz aus Tabelle B ist maximal ein Datensatz aus Tabelle A zugeordnet.
- 1:n-Beziehung: Jeder Datensatz aus Tabelle A kann mit mehreren Datensätzen aus Tabelle B verknüpft sein, aber jedem Datensatz aus Tabelle B ist maximal ein Datensatz aus Tabelle A zugeordnet.
- n:m-Beziehung: Jeder Datensatz aus Tabelle A kann mit mehreren Datensätzen aus Tabelle B verknüpft sein und jeder Datensatz aus Tabelle B kann mit mehreren Datensätzen aus Tabelle A verknüpft sein.
Primär- und Fremdschlüssel #
Die genannten Beziehungen werden durch Primär- und Fremdschlüssel hergestellt. In einer relationalen Datenbank besitzt jede Zeile einer Tabelle eine Kennung (ID), die den Datensatz eindeutig identifiziert. Diese Zeilen-ID wird als Primärschlüssel der Datenbank bezeichnet.
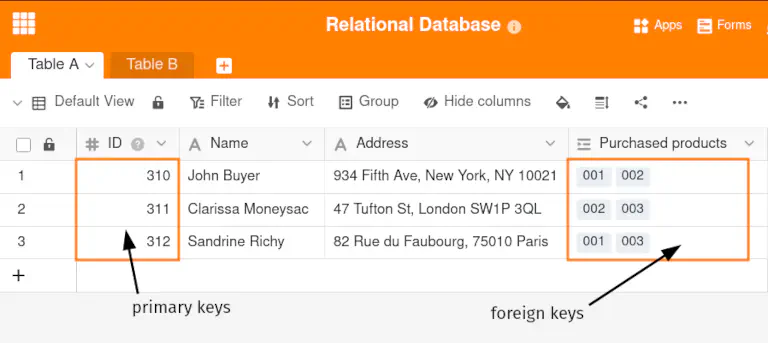
Unter einem Fremdschlüssel in einer Datenbank versteht man die verknüpfte Spalte, also das Attribut einer Tabelle, das auf einen Primärschlüssel in derselben oder einer anderen Tabelle verweist.
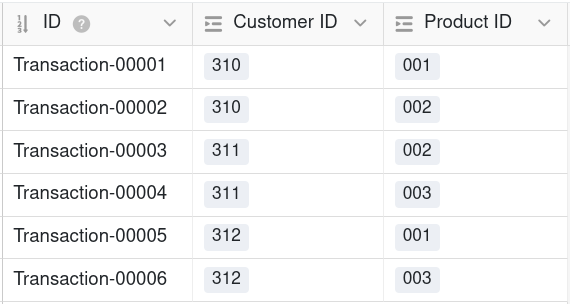
Demnach stellt eine relationale Datenbank die Verknüpfung zweier Tabellen sowohl bei einer 1:1-Beziehung als auch bei einer 1:n-Beziehung her, indem Tabelle B die Primärschlüssel der Datensätze aus Tabelle A als Fremdschlüssel erhält. Für eine n:m-Beziehung benötigt sie jedoch eine weitere Tabelle, welche die Primärschlüssel von beiden verknüpften Datensätzen als Fremdschlüssel in einer Zeile vereint.
Die ACID-Eigenschaften #
Die folgenden ACID-Eigenschaften gewährleisten die Datenintegrität und die Zuverlässigkeit von Transaktionen in relationalen Datenbanken:
- Atomarität stellt sicher, dass Transaktionen entweder vollständig oder gar nicht ausgeführt werden, was Datenverlust und unvollständige Transaktionen verhindert.
- Konsistenz garantiert, dass Transaktionen alle definierten Regeln der Datenbank einhalten, sodass die Daten anschließend korrekt vorliegen.
- Isolation sorgt dafür, dass parallele Transaktionen sich nicht gegenseitig beeinflussen, sondern für andere unsichtbar bleiben, bis sie abgeschlossen sind.
- Dauerhaftigkeit bedeutet, dass die Daten nach Abschluss einer Transaktion permanent gespeichert werden.
Diese Prinzipien reduzieren nicht nur fehlerhafte Daten, sondern auch die Auswirkungen von Systemausfällen auf ein Minimum. Dadurch, dass der Zustand eines relationalen Datenbanksystems zu jedem Zeitpunkt konsistent ist, können Sie Daten schnell und einfach exportieren, importieren und wiederherstellen.
Vorteile von relationalen Datenbanken #
Als Datenbanken noch in den Kinderschuhen steckten, speicherte jede Anwendung die Daten in ihrer eigenen hierarchischen oder vernetzten Struktur. Diese Datenstrukturen waren ineffizient, unflexibel und schwer zu warten. Erst das relationale Modell löste dieses Problem, indem es eine tabellarische Datenbanklogik einführte, die bis heute eine effiziente Speicherung und Abfrage der Daten ermöglicht.
Ein weiterer Vorteil relationaler Datenbanken ist ihre Flexibilität und Anpassungsfähigkeit bei Veränderungen. Es ist kinderleicht, Tabellen und Datensätze hinzuzufügen, zu aktualisieren oder zu löschen, ohne die gesamte Datenbankstruktur überarbeiten zu müssen. Das erleichtert die Verwaltung großer Datenmengen. Zudem bieten Tabellen eine intuitive Darstellung der Daten und einen schnellen Zugriff auf verknüpfte Datensätze.
Einer der größten Vorteile, die ein relationales Datenbankmodell mit sich bringt, ist die referenzielle Integrität. Sie stellt sicher, dass jeder Fremdschlüsselwert in Bezug auf den zugehörigen Primärschlüssel existiert. Dies verhindert Dateninkonsistenzen und sorgt dafür, dass alle Beziehungen zwischen den Datensätzen korrekt sind.
Auch wenn mehrere Benutzer gleichzeitig mit den Datensätzen arbeiten, bleibt die Datenkonsistenz gewahrt. Darüber hinaus hat ein relationales Datenbankmodell Vorteile gegenüber nicht-relationalen Datenbanken, weil die Normalisierung unerwünschte Redundanzen und Anomalien verringert.

SQL in relationalen Datenbanken #
Die Structured Query Language (SQL) wurde speziell für relationale Datenbanken entwickelt und hat sich als weit verbreitete Datenbanksprache etabliert. Ursprünglich entstand sie aus einem Vorläufer namens SEQUEL (Structured English Query Language), weshalb diese Aussprache auch heute noch üblich ist. Sie ermöglicht es, Daten in Tabellen hinzuzufügen, zu ändern oder zu löschen sowie komplexe Datenbankabfragen durchzuführen. Daher spielt SQL eine zentrale Rolle bei der Verwaltung relationaler Datenbanken.
Unterschiede zwischen relationalen und nicht-relationalen Datenbanken #
Nicht-relationale Datenbanken, auch NoSQL-Datenbanken genannt, sind ein Sammelbegriff für alle Datenbanken, denen kein relationales Datenbankmodell zugrunde liegt. Hierzu zählen insbesondere:
- dokumentenorientierte Datenbanken
- objektorientierte Datenbanken
- spaltenorientierte Datenbanken
- Graph-Datenbanken
- Schlüssel-Werte-Datenbanken
Wie die Namen schon andeuten, speichern NoSQL-Lösungen Daten nicht in Tabellen, sondern beispielsweise als Dokumente, Objekte, Spalten, Graphen oder Schlüssel-Wert-Paare.
Horizontale vs. vertikale Skalierung #
Eine nicht relationale Datenbank ist darauf ausgelegt, unstrukturierte Daten in großen Mengen (Big Data) zu verarbeiten und horizontal zu skalieren, also die Last auf verschiedene Server zu verteilen. Dahingegen skaliert eine relationale Datenbank vertikal auf einem einzigen Server. Das heißt, man muss die Leistung des Servers (CPU, RAM) erhöhen, um Big Data zu verarbeiten.

Deshalb haben relationale Datenbanken üblicherweise Performance-Probleme bei datenintensiven Anwendungen wie zum Beispiel Video-Streaming und können schlecht damit umgehen, wenn gleichzeitig viele Änderungen in großen Datenmengen auftreten. Dennoch ist eine relationale Datenbank optimal für häufige, aber kleine Datenänderungen oder große Datenmengen mit seltenen Änderungen geeignet.
Eine nicht relationale Datenbank kann selbst bei riesigen Datenmengen mit vielen gleichzeitigen Zugriffen und Änderungen umgehen. Allerdings bieten NoSQL-Architekturen meist wenig Transaktionssicherheit und Datenintegrität, was sie für geschäftskritische Anwendungen wie Finanztransaktionen unbrauchbar macht.
Hier noch einmal die Unterschiede zwischen relationalen und nicht-relationalen Datenbanken im Überblick:
| Aspekt | relationale Datenbank | nicht-relationale Datenbank |
|---|---|---|
| Datenorganisation | strukturierte Daten in Tabellen | unstrukturierte Daten (z. B. Dokumente) |
| Sprache | SQL | unterschiedlich (z. B. YAML) |
| Skalierung | vertikal | horizontal |
| Transaktionssicherheit | hoch | gering |
| Datenintegrität | stark | schwach |
Worauf Sie bei der Auswahl einer Datenbank achten sollten #
Wenn Sie eine Auswahl zwischen verschiedenen Datenbanktypen treffen müssen, sollten Sie bestimmte Faktoren bei Ihrer Entscheidung berücksichtigen. Stellen Sie sich unter anderem folgende Fragen:
- Möchten Sie eher strukturierte Daten oder unstrukturierte Daten (z. B. Dokumente) speichern?
- Wie hoch sind Ihre Anforderungen an die Datenintegrität und Zuverlässigkeit der Datenbank?
- Wie groß sind die zu erwartenden Datenmengen und welche Skalierbarkeit ist erforderlich?
- Benötigen Sie eine agile Datenverwaltung, weil Sie schnell und flexibel Anpassungen machen möchten oder mehrere Benutzer gleichzeitig auf die Daten zugreifen müssen?
- Wie häufig werden Datenänderungen auftreten und welche Rückschlüsse folgen daraus für die notwendige Leistungsfähigkeit der Datenbank?
Verwendung von relationalen Datenbanken in der Praxis #
Eine relationale Datenbank ist das Mittel der Wahl, wenn Sie eine zuverlässige, genaue und effiziente Datenverwaltung gewährleisten wollen. Daher werden relationale Datenbanken in der Praxis oft für geschäftskritische Prozesse eingesetzt, bei denen die Aufrechterhaltung der Datenintegrität besonders wichtig ist. Zum Beispiel sind sie ideal für die Verarbeitung von
- Finanztransaktionen (z. B. Zahlungen)
- Bestandsdaten in der Lagerverwaltung
- Kundeninformationen in CRM-Systemen
- zentralen Stammdaten
Aufgrund ihrer Flexibilität bei gleichzeitiger Stringenz in der Datenstruktur sind relationale Datenbanken aber auch für viele weitere Anwendungsfälle geeignet. Meist bilden sie das Herzstück von Data Warehouses .
Beispiele für relationale Datenbankmanagementsysteme (RDBMS) #
Klassische Datenbanken #
Weit verbreitete relationale Datenbankmanagementsysteme (RDBMS) sind beispielsweise MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server und IBM DB2. Jedes dieser RDBMS hat seine Stärken und Schwächen. Was für ein relationales Datenbanksystem am besten passt, hängt stark von den konkreten Anforderungen Ihres Unternehmens ab.
No-Code-Datenbanken #
In den letzten Jahren haben sich zudem No-Code-Plattformen wie SeaTable auf dem Markt etabliert, die eine visuelle Benutzeroberfläche mit einer relationalen Datenbank vereinen. So können Sie und Ihre Mitarbeiter ohne jegliche Programmierkenntnisse relationale Datenbanken, Anwendungen und Prozesse erstellen und diese ohne SQL-Abfragen nutzen.
SeaTable – die relationale No-Code-Datenbank für agile Datenverwaltung #
SeaTable ist eine KI No-Code-Plattform , die auf ein relationales Datenbankmodell setzt. Sie ist dafür gemacht, strukturierte Daten in Tabellen zu erfassen, kann aber dank einer speziellen Dateiverwaltung auch mit unstrukturierten Daten (z. B. Bildern, Dokumenten) umgehen. Der große Unterschied zu klassischen relationalen Datenbanken ist die visuelle Benutzeroberfläche, die es jedem ermöglicht, ohne SQL-Kenntnisse Daten auszuwerten und zu bearbeiten sowie Datenbanken, Workflows und Apps zu bauen.
SeaTable bringt eine hohe Flexibilität mit und hilft Ihnen, Ihre Prozesse individuell zu gestalten, zu optimieren und zu automatisieren. Nutzen Sie auch KI-Funktionen, um Ihr Datenmanagement noch effizienter zu machen. Außerdem haben Sie die freie Wahl, ob Sie den Komfort und die Skalierbarkeit der SeaTable Cloud genießen möchten oder lieber SeaTable Server On-Premises installieren, um die volle Datenhoheit zu behalten. Starten Sie mit der kostenlosen Version und überzeugen Sie sich selbst!
Ausblick: Zukunftsaussichten für relationale Datenbanken #
Die Zukunft relationaler Datenbanken wird stark von der Frage geprägt sein, wie künstliche Intelligenz den Umgang mit Daten vereinfachen und Routineaufgaben automatisieren kann. Gut, dass SeaTable die Zeichen der Zeit erkannt und bereits KI-Automationen in seine relationale Datenbank integriert hat.
Zudem verlagern sich relationale Datenbanken zunehmend in die Cloud , weil diese Technologie eine höhere Skalierbarkeit, Verfügbarkeit und Leistung bei der Verarbeitung großer Datenmengen verspricht.
Nicht zuletzt werden No-Code-Datenbanken stärker in Erscheinung treten, da sie eine einfache und schnelle Datenverarbeitung und -abfrage ohne SQL-Kenntnisse möglich machen, den Nutzerkreis um Citizen Developer erweitern und sich noch flexibler an wechselnde Anforderungen der agilen Datenverwaltung anpassen können.
Häufige Fragen zu relationalen Datenbanken #
Was ist eine relationale Datenbank?
Was ist SQL?
Welche Unterschiede gibt es zwischen relationalen und nicht-relationalen Datenbanken?
Welche Vorteile haben relationale Datenbanken?
Was versteht man unter den ACID-Eigenschaften?