
What is a data warehouse? #
A data warehouse (also abbreviated to DWH) is a central storage system that brings together large amounts of data from different sources, structures it and prepares it for analysis. By storing and visualizing the history of the data, you can identify patterns, trends and correlations over time. This is why business intelligence also plays an important role in data warehouses.
The analysis functions enable you to derive valuable insights into various business areas from your data in order to improve decision-making. If you incorporate all of your company’s data into your data warehouse, it can even be described as a single source of truth – i.e. a complete and reliable database.
The advantages of a data warehouse #
- Make decisions easier: With the help of a solid database, you can make informed decisions.
- Improve data quality: A data warehouse cleanses, consolidates and standardizes large amounts of data to make it usable.
- Visualize correlations: In a data warehouse system, you can create analyses, reports and presentations in no time at all.
- Recognize developments: In the data warehouse, you collect long-term historical progress data from which you can derive patterns, trends and forecasts.
The 4 main features of data warehouses #
The American computer scientist Bill Inmon, who is considered the “father of data warehousing”, defines four characteristics of data warehouses.
- Theme-oriented: The first step is to select the data and key figures for a specific topic or business area (e.g. sales, finance, HR) to be included in the DWH. What information is required for subsequent analysis and decision-making?
- Integrated: A data warehouse centralizes, standardizes and cleanses data from various sources and stores it in a structured form. This ensures a high level of data consistency.
- Time-oriented: Historical data, which allows you to view changes over time, is the focus of data warehousing. Long-term data storage is necessary so that you can analyze developments over time.
- Non-volatile: Once data has been stored in the data warehouse, you must not change or delete it - otherwise the history will be distorted. It is therefore important that the data is not volatile, but stable.
History and future of data warehousing #
The first data warehouses came onto the market at the end of the 1980s. At that time, they were intended to supply existing decision support systems and management information systems with data.
-
Decision support systems (DSS) were the first software solutions that allowed data modeling and simulations to support decision-making.
-
Management information systems (MIS) were designed to simplify manual data preparation and the creation of graphical evaluations for top management.
However, the data warehouses of the time had to cope with enormous redundancy because many companies had several DSS and FIS for different business areas. Although the systems mostly used the same data, the data was often stored separately for each environment. However, with the rise of business intelligence platforms, the data warehouse has evolved into a more efficient information repository with comprehensive analytics capabilities for different business units.

Today, AI , machine learning and automation are opening up entirely new possibilities to improve the performance of data warehouses. This development ultimately leads to autonomous data warehouses that are completely self-managing and no longer require human administration. This can relieve the burden on your company’s IT department and free up time to gain even more insights from your data. At the same time, you can reduce costs with a modern data warehouse and design optimal data warehouse architectures for the requirements of different users and specialist areas.
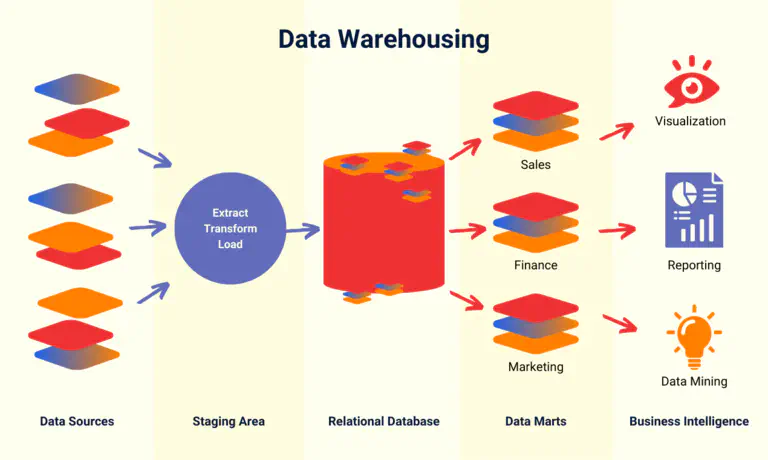
How a data warehouse is structured #
Exactly how you configure your data warehouse system depends on the specific data warehouse requirements of your company, which you should first define. However, all data warehouse architectures share a basic design: raw data is temporarily stored in a repository that is fed by data sources on the one hand and writes structured data to a relational database on the other. Users then access the cleansed data via BI tools for analysis, visualization and reporting.
Key components of data warehousing #
A typical data warehouse concept can be divided into the following levels:
- Internal data sources, e.g. ERP and CRM systems, or external data sources such as IoT devices or social media platforms provide raw data.
- the raw data is temporarily stored and transformed in a staging area. In the ETL process, the data warehouse transforms the data for structured storage.
- the core of the data warehouse is usually a relational database, which stores and manages the structured and cleansed data.
- a data warehouse is usually divided into several data marts. These focus on subject-specific areas or individual departments (e.g. sales, marketing, finance).
- the data mining, statistical data analysis, graphical visualization and reporting are carried out with BI tools such as Tableau, Microsoft Power BI or Google Looker.
ETL process for efficient data warehouse management #
A data warehouse uses so-called ETL processes to collect data from various sources, transform it and load it into the central database. The abbreviation stands for Extract, Transform, Load. The ETL process takes place in three steps in the staging area:
- the extraction: The data warehouse collects the desired data from various sources. For this to work, you usually have to connect other systems to the data warehouse system via an API.
- the transformation: This involves cleansing, enriching and uniformly formatting the data. For example, the data warehouse removes duplicates, adds missing values and adapts the data types.
- the loading: Finally, the cleansed data is transferred to the central database.
Example of a data warehouse process #
The previous explanations were quite technical. Here we have another illustrative example for you, which clearly shows how a data warehouse process runs smoothly.
Let’s assume you run an online shop and want to analyze sales, access figures and customer data. First of all, you need to think about which data sources you want to include in your data warehouse and which systems you need to tap into. In this case, this could be the order history from Shopify, the web traffic from Google Analytics and the CRM data from Pipedrive . This data is now cleansed, harmonized and stored in the data warehouse. You can now statistically evaluate all sales and access figures, carry out customer analyses and draw conclusions for your sales strategy and the improvement of your online store.

Differences between a data warehouse and a database #
Data warehouse and database are two different data management systems . While a database usually focuses on the storage of data, the data warehousing system maps a longer process from data acquisition through data integration and preparation to data analysis. Nevertheless, data warehouses also store huge amounts of data in a central database, which is the heart of every DWH solution. In turn, a data warehouse serves as the basis for analyses and reporting throughout the company.
| Data Warehouse | Database | |
|---|---|---|
| Purpose / Focus | Analyses & Reports | Data Storage |
| Reach | usually company-wide | variable |
What is the difference between a data warehouse and a data lake? #
A data lake is a kind of collection basin for all the raw data of an organization. This can be structured data from relational databases as well as unstructured data (e.g. emails, PDF documents and image files). In contrast to a data warehouse, however, a data lake stores the data unadjusted until you want to prepare it for analysis or visualization as required. You can therefore literally imagine the data lake as a data lake in which data from different sources flows together and initially rests unprocessed. Data lakes such as Amazon S3, Microsoft Azure Data Lake or Google Cloud Storage therefore enable fast and flexible storage of large amounts of data.

The two basic data warehouse technologies #
There are various data warehouse solutions on the market, which can basically be divided into cloud or on-premises. Originally, data warehouses were only provided on on-premises servers. Even today, these local data warehouses can still have certain advantages in terms of security and data sovereignty . However, the administration of these systems can be very time-consuming for complex data warehouse architectures.
Advantages of “Data Warehouse in the Cloud” #
A data warehouse in the cloud has the following advantages, among others:
- Elasticity and scalability: Since you have a cloud data warehouse hosted in a data center, you have almost unlimited computing power and storage space at your disposal. Depending on the amount of data, you can flexibly expand or reduce the capacities used, i.e. scale up or down.
- Lower operating costs: With DWH in the cloud, you don’t have to invest in your infrastructure, hire additional staff and only pay for the amount of resources you actually need (pay-as-you-go principle).
- Rapid deployment: You can create a cloud data warehouse in a short time thanks to ready-made processes and customize it according to your requirements, whereas an on-premises setup can take several months and involves a lot of development work.
- Real-time data: In-memory DWH technologies enable data processing at breakneck speed. Based on real-time data, you can immediately identify and analyze sudden changes.
Below is an overview of the differences between cloud and on-premises.
| Cloud | On-Premises | |
|---|---|---|
| Delivery | Setup possible anywhere in the world in a short time | On-site hardware setup can take several weeks |
| Costs | Pay-as-you-go principle, no additional costs for infrastructure and personnel | High acquisition and operating costs for infrastructure and personnel |
| Scalability | flexible, automatic scaling without limits | manual capacity planning with clear limits |
| Security | high encryption, automatic backups | full control and data sovereignty, security dependent on your IT processes |
| Real-time updating | very fast thanks to in-memory technology | often batch-based with delays |
| Operability | often user-friendly thanks to prefabricated elements, no IT dependency | often complex, IT experts have to connect the data sources and administer the DWH |
SeaTable – the flexible, simple and cost-effective data warehouse #
SeaTable is a no-code platform that offers the advantage over other relational databases that users can work on an intuitive graphical user interface without SQL or other IT knowledge. With the help of various views, plugins and statistics, you can easily prepare and visualize the data the way you want. This makes it easier for you to carry out precise analyses and make well-founded decisions without any headaches.
Data from countless sources can flow into SeaTable via integrations with Zapier, Make or n8n and the SeaTable API. To enable SeaTable to store all data in a structured form, select the desired data types in advance. Thanks to the user-friendly modular principle, this is just as easy as using the integrated App Builder to create your own apps . SeaTable also enables team collaboration and updates data in real time - changes are immediately visible to all users and fully documented in the version history.
What’s more, you can choose whether you want to operate your data warehouse on-premises or in the cloud. Benefit from the scalability and convenience of the SeaTable Cloud or host SeaTable Server on your own servers with full control and data sovereignty. Start with the free basic version, which you can upgrade to a Plus or Enterprise subscription at any time as soon as you need more functions or storage space.
Register for free and experience how easy data warehousing can be.
FAQs on data warehousing #
What is a data warehouse?
What is a data lake?
What is a data mart?
What does ETL mean?
TAGS: Data Management & Visualisation Digital Transformation