
Qu’est-ce qu’un entrepôt de données ? #
Un entrepôt de données (également abrégé DWH) est un système de stockage central qui rassemble de grandes quantités de données provenant de différentes sources, les structure et les prépare à des fins d’analyse. En enregistrant et en visualisant l’historique des données, il est possible d’identifier des modèles, des tendances et des corrélations dans le temps. C’est pourquoi la Business Intelligence joue également un rôle important dans les entrepôts de données.
Les fonctions d’analyse vous permettent d’extraire de vos données des connaissances précieuses sur différents domaines d’activité afin d’améliorer la prise de décision. Si vous intégrez toutes les données de votre entreprise dans votre entrepôt de données, on peut même le qualifier de Single Source of Truth, c’est-à-dire de base de données complète et fiable.
Les avantages d’un entrepôt de données #
- Faciliter la prise de décision : Grâce à une base de données solide, vous pouvez prendre des décisions en connaissance de cause.
- Améliorez la qualité des données : Un entrepôt de données nettoie, consolide et standardise de grandes quantités de données afin de les rendre utilisables.
- Montrer les relations de cause à effet : Dans un système d’entrepôt de données, vous créez des analyses, des rapports et des présentations en un clin d’œil.
- Déceler les évolutions : Dans un entrepôt de données, vous collectez des données historiques à long terme, à partir desquelles vous pouvez déduire des modèles, des tendances et des prévisions.
Les 4 principales caractéristiques des entrepôts de données #
L’informaticien américain Bill Inmon, considéré comme le “père du data warehousing”, définit quatre caractéristiques des entrepôts de données.
- Orientation thématique : Tout d’abord, on sélectionne les données et les chiffres clés relatifs à un thème ou à un secteur d’activité spécifique (par exemple, ventes, finances, RH) qui doivent être intégrés dans le DWH. Quelles informations sont nécessaires pour l’analyse et la prise de décision ultérieures ?
- Intégré : Un entrepôt de données centralise, uniformise et nettoie les données provenant de différentes sources et les stocke sous une forme structurée. Il assure ainsi une grande cohérence des données.
- Orienté dans le temps : Les données historiques, qui vous permettent d’observer les changements dans le temps, sont au centre du data warehousing. Pour que vous puissiez analyser les évolutions au fil du temps, il est nécessaire de stocker les données à long terme.
- Non volatile : Une fois que les données sont enregistrées dans le datawarehouse, vous ne pouvez plus les modifier ou les supprimer - sinon, l’historique est faussé. Il est donc important que les données ne soient pas volatiles, mais stables.
Histoire et avenir du data warehousing #
Les premiers entrepôts de données sont apparus sur le marché à la fin des années 1980. À l’époque, ils devaient alimenter en données les systèmes d’aide à la décision et les systèmes d’information de gestion déjà existants.
-
Les Systèmes d’aide à la décision (SAD) ont été les premières solutions logicielles à permettre la modélisation des données et les simulations afin d’aider à la prise de décision.
-
Les systèmes d’information de gestion (SIG) devaient simplifier la préparation manuelle des données et la création d’analyses graphiques pour le top management.
Cependant, les entrepôts de données de l’époque devaient faire face à une énorme redondance, car de nombreuses entreprises possédaient plusieurs DSS et FIS pour différents secteurs d’activité. Même si les systèmes utilisaient principalement les mêmes données, celles-ci étaient souvent stockées séparément pour chaque environnement. Mais avec l’essor des plates-formes de Business Intelligence, l’entrepôt de données a également évolué vers un stockage d’informations plus efficace avec des fonctions d’analyse complètes pour différents domaines d’activité.

Aujourd’hui, l’IA , l’apprentissage automatique et l’automatisation ouvrent de toutes nouvelles possibilités pour améliorer les performances des entrepôts de données. Cette évolution aboutit finalement à des entrepôts de données autonomes qui se gèrent entièrement eux-mêmes et ne nécessitent plus d’administration humaine. Cela peut décharger le service informatique de votre entreprise et lui permettre d’obtenir encore plus de connaissances à partir de vos données. En même temps, un entrepôt de données moderne vous permet de réduire les coûts et de concevoir des architectures d’entrepôt de données optimales pour les besoins de différents utilisateurs et domaines spécialisés.
Comment un entrepôt de données est-il structuré ? #
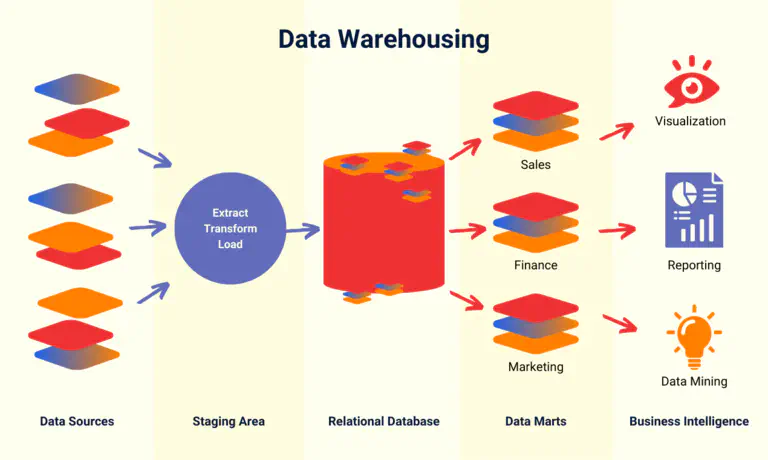
La manière exacte de configurer votre système d’entrepôt de données dépend des besoins spécifiques de votre entreprise en matière d’entrepôt de données, que vous devez d’abord définir. Toutes les architectures d’entrepôt de données partagent cependant une conception de base : les données brutes sont stockées temporairement dans un référentiel qui est alimenté d’une part par des sources de données et qui écrit d’autre part des données structurées dans une base de données relationnelle . Au final, les utilisateurs accèdent aux données nettoyées via des outils de BI pour l’analyse, la visualisation et la création de rapports.
Composants clés de l’entreposage de données #
Un concept typique d’entrepôt de données peut être divisé selon les niveaux suivants :
- Les sources de données internes, par exemple les systèmes ERP et CRM, ou les sources de données externes, comme les appareils IoT ou les plateformes de médias sociaux, fournissent des données brutes.
- Les données brutes sont temporairement stockées et transformées dans une Staging Area. Lors du processus ETL, l’entrepôt de données transforme les données pour un stockage structuré.
- Le cœur du datawarehouse est généralement constitué d’une base de données relationnelle qui stocke et gère les données structurées et nettoyées.
- Un entrepôt de données se divise généralement en plusieurs marchés de données. Ceux-ci se concentrent sur des domaines spécialisés ou sur des départements individuels (par ex. ventes, marketing, finances).
- Le Data Mining, l’analyse statistique des données, la visualisation graphique et le reporting sont réalisés à l’aide d’outils BI tels que Tableau, Microsoft Power BI ou Google Looker.
Processus ETL pour une gestion efficace de l’entrepôt de données #
Pour collecter des données provenant de différentes sources, les transformer et les charger dans la base de données centrale, un entrepôt de données utilise des processus dits ETL. L’abréviation signifie Extract, Transform, Load. Le processus ETL se déroule en trois étapes sur la Staging Area :
- l’extraction : Le datawarehouse collecte les données souhaitées à partir de différentes sources. Pour que cela fonctionne, il est généralement nécessaire de connecter d’autres systèmes au système d’entrepôt de données via une API.
- la transformation : Il s’agit ici de nettoyer les données, de les enrichir et de les formater de manière uniforme. Pour ce faire, l’entrepôt de données supprime par exemple les doublons, ajoute les valeurs manquantes et adapte les types de données.
- le chargement : Pour finir, les données nettoyées sont transférées dans la base de données centrale.
Exemple de processus d’entrepôt de données #
Les explications données jusqu’ici étaient assez techniques. Nous vous proposons ici un autre exemple clair qui montre comment un processus d’entrepôt de données se déroule sans problème.
Supposons que vous exploitiez une boutique en ligne et que vous souhaitiez analyser les ventes, le nombre de visites et les données clients. Vous devez donc d’abord déterminer quelles sources de données doivent être intégrées dans votre entrepôt de données et quels systèmes vous devez utiliser à cet effet. Dans ce cas, il pourrait s’agir de l’historique des commandes de Shopify, du trafic web de Google Analytics et des données CRM de Pipedrive . Ces données sont maintenant nettoyées, harmonisées et stockées dans le datawarehouse. Vous pouvez maintenant évaluer statistiquement toutes les ventes et les chiffres d’accès, effectuer des analyses de clients et en tirer des conclusions pour votre stratégie de vente et l’amélioration de votre boutique en ligne.

Différences entre un entrepôt de données et une base de données #
L’entrepôt de données et la base de données sont deux systèmes de gestion de données différents. Alors qu’une base de données se focalise généralement sur le stockage de données, le système d’entrepôt de données reproduit un processus plus long, de l’acquisition des données à l’analyse des données en passant par l’intégration et la préparation des données. Néanmoins, les entrepôts de données stockent également d’énormes quantités de données dans une base de données centrale, qui constitue le cœur de toute solution DWH. Un entrepôt de données sert à son tour de base pour les analyses et les rapports dans toute l’entreprise.
| Entrepôt de données | Base de données | |
|---|---|---|
| Objectif / Focus | Analyses & Rapports | Stockage des données |
| Couverture | généralement à l’échelle de l’entreprise | variable |
Quelle est la différence entre un entrepôt de données et un lac de données ? #
Un Data Lake est pour ainsi dire un bassin de collecte de toutes les données brutes d’une organisation. Il peut s’agir aussi bien de données structurées issues de bases de données relationnelles que de données non structurées (par exemple des e-mails, des documents PDF et des fichiers image). Contrairement à un entrepôt de données, un data lake stocke toutefois les données non nettoyées jusqu’à ce que vous souhaitiez les préparer pour l’analyse ou la visualisation si nécessaire. Par conséquent, vous pouvez littéralement vous représenter le data lake comme un lac de données dans lequel les données provenant de différentes sources convergent et reposent d’abord sans être traitées. Les Data Lakes tels qu’Amazon S3, Microsoft Azure Data Lake ou Google Cloud Storage permettent donc d’absorber rapidement et de manière flexible de grandes quantités de données.

Les deux technologies de base des entrepôts de données #
Il existe sur le marché différentes solutions d’entrepôts de données, qui peuvent être classées en principe en cloud ou sur site. À l’origine, les entrepôts de données étaient uniquement mis à disposition sur des serveurs sur site. Ces entrepôts de données locaux peuvent encore aujourd’hui présenter certains avantages en termes de sécurité et de souveraineté des données . Toutefois, leur gestion peut s’avérer très lourde dans le cas d’architectures d’entrepôts de données complexes.
Avantages des “entrepôts de données dans le cloud #
Un entrepôt de données dans le nuage présente notamment les avantages suivants :
- élasticité et évolutivité : Comme vous faites héberger un entrepôt de données en nuage dans un centre de données, vous disposez d’une puissance de calcul et d’un espace de stockage quasiment illimités. En fonction de la quantité de données, vous pouvez augmenter ou diminuer les capacités utilisées de manière flexible, c’est-à-dire les faire évoluer vers le haut ou vers le bas.
- Coûts d’exploitation réduits : Avec le DWH dans le cloud, vous n’avez pas besoin d’investir dans votre infrastructure, vous n’avez pas besoin d’engager du personnel supplémentaire et vous ne payez que pour la quantité de ressources dont vous avez réellement besoin (principe du “pay-as-you-go”).
- Déploiement rapide : Grâce à des processus prédéfinis, vous pouvez créer un entrepôt de données en nuage en peu de temps et l’adapter à vos besoins, alors qu’une configuration sur site peut prendre plusieurs mois et nécessiter un développement important.
- Données en temps réel : Les technologies DWH en mémoire permettent de traiter les données à une vitesse fulgurante. Sur la base des données en temps réel, vous pouvez identifier et analyser immédiatement les changements soudains.
Ci-dessous, vous trouverez un aperçu des différences entre le cloud et le sur site.
| Cloud | On-Premises | |
|---|---|---|
| Déploiement | Configuration possible partout dans le monde en peu de temps | Configuration du matériel sur site pouvant prendre plusieurs semaines |
| Coûts | principe du “pay-as-you-go”, pas de coûts supplémentaires pour l’infrastructure et le personnel | coûts d’acquisition et d’exploitation élevés pour l’infrastructure et le personnel |
| Évolutivité | mise à l’échelle flexible et automatique sans limites | planification manuelle des capacités avec des limites claires |
| Sécurité | cryptage élevé, sauvegardes automatiques | contrôle total et souveraineté des données, sécurité dépendant de vos processus informatiques |
| Mise à jour en temps réel | très rapide grâce à la technologie in-memory | souvent basée sur le traitement par lots avec des retards |
| Utilisation | souvent conviviale grâce à des éléments prédéfinis, pas de dépendance informatique | souvent complexe, les experts informatiques doivent connecter les sources de données et administrer le DWH |
SeaTable – l’entrepôt de données flexible, simple et économique #
SeaTable est une plate-forme sans code qui présente l’avantage, par rapport à d’autres bases de données relationnelles, de permettre aux utilisateurs de travailler sur une interface utilisateur graphique intuitive sans avoir besoin de SQL ou d’autres connaissances informatiques. À l’aide de différents affichages, plug-ins et statistiques, vous pouvez facilement préparer et visualiser les données comme vous le souhaitez. Cela vous permet de réaliser des analyses précises et de prendre des décisions éclairées sans vous casser la tête.
Grâce aux intégrations avec Zapier, Make ou n8n et à l’API SeaTable, les données provenant d’innombrables sources peuvent converger vers SeaTable. Pour que SeaTable puisse stocker toutes les données sous forme structurée, il suffit de sélectionner au préalable les types de données souhaités. C’est aussi facile grâce au principe modulaire convivial que de créer ses propres applications grâce au constructeur d’applications intégré . De plus, SeaTable permet la collaboration en équipe et actualise les données en temps réel – les modifications sont immédiatement visibles pour tous les utilisateurs et entièrement documentées dans l’historique des versions.
De plus, vous pouvez choisir d’exploiter votre entrepôt de données sur site ou dans le nuage. Profitez de l’évolutivité et du confort du SeaTable Cloud ou hébergez SeaTable Server sur vos propres serveurs avec un contrôle total et la souveraineté des données. Commencez avec la version de base gratuite, que vous pouvez mettre à niveau à tout moment vers un abonnement Plus ou Enterprise dès que vous avez besoin de plus de fonctionnalités ou d’espace de stockage.
Inscrivez-vous gratuitement et découvrez à quel point l’entreposage de données peut être simple.
FAQ sur le data warehousing #
Qu'est-ce qu'un entrepôt de données ?
Qu'est-ce qu'un data lake ?
Qu'est-ce qu'un data mart?
Que signifie ETL ?
TAGS: