
Principales conclusiones #
- Una base de datos relacional organiza los datos en tablas de filas y columnas y las relaciona entre sí.
- Ella vincula las tablas entre sí mediante claves primarias y externas, lo que minimiza los datos redundantes y permite almacenar y recuperar datos con eficacia.
- SQL es el lenguaje de base de datos estándar para recuperar, insertar, modificar o eliminar datos en bases de datos relacionales.
- La mayor ventaja de las bases de datos relacionales es la integridad de los datos y la seguridad de las transacciones, que se debe a las propiedades ACID (atomicidad, consistencia, aislamiento, durabilidad).
¿Qué es una base de datos relacional? #
Una base de datos relacional es, ante todo, una colección de información estructurada. Almacena los datos en tablas formadas por filas y columnas y establece relaciones entre las tablas mediante claves. Utiliza SQL como estándar para consultas y cambios, garantiza una alta integridad de los datos (principios ACID) y es perfecta para gestionar datos estructurados en grandes cantidades.
¿Cómo funciona una base de datos relacional? #
Las bases de datos relacionales se basan en un concepto fundamental conocido como modelo relacional. El modelo de base de datos relacional fue desarrollado en 1970 por el matemático británico Edgar F. Codd y sigue siendo el estándar para las bases de datos hoy en día, a pesar de la aparición de soluciones NoSQL.
Veamos más de cerca el diseño y la estructura de las bases de datos relacionales.
Tablas y relaciones #
Las bases de datos relacionales almacenan la información en forma de tablas. Cada tabla consta de filas y columnas, y cada fila representa un registro de datos. Cada columna define un atributo de los registros de datos, de modo que, por regla general, cada registro de datos tiene un valor para cada atributo.
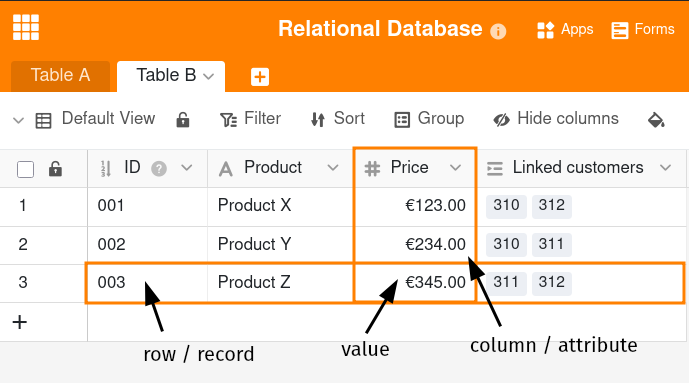
Esta estructura clara de las bases de datos relacionales permite almacenar datos en tablas diferentes y vincularlos mediante relaciones. Una relación es una conexión lógica entre dos tablas. Incluso un modelo simplificado de base de datos relacional consistente en las tablas A y B permite distintos tipos de relaciones:
- Relación 1:1: A cada registro de datos de la tabla A se le asigna como máximo un registro de datos de la tabla B y a cada registro de datos de la tabla B se le asigna como máximo un registro de datos de la tabla A.
- Relación 1:n: Cada registro de datos de la tabla A puede estar vinculado a varios registros de datos de la tabla B, pero a cada registro de datos de la tabla B se le asigna como máximo un registro de datos de la tabla A.
- Relación n:m: Cada registro de datos de la tabla A puede estar vinculado a varios registros de datos de la tabla B y cada registro de datos de la tabla B puede estar vinculado a varios registros de datos de la tabla A.
Claves primarias y externas #
Las relaciones mencionadas se crean utilizando claves primarias y externas. En una base de datos relacional, cada fila de una tabla tiene un identificador (ID) que identifica unívocamente el registro de datos. Este identificador de fila se denomina clave primaria de la base de datos.
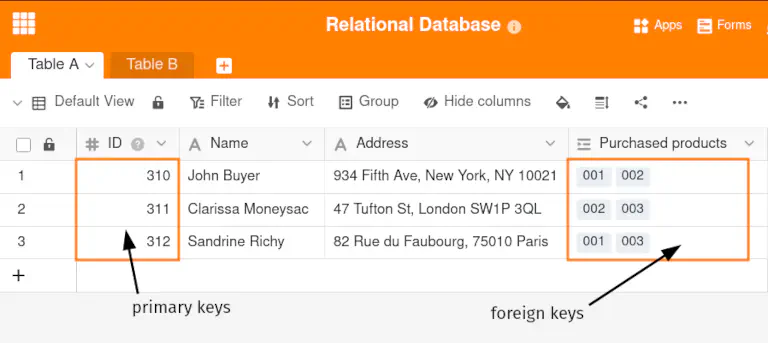
Una clave externa en una base de datos es la columna vinculada, es decir, el atributo de una tabla que hace referencia a una clave primaria de la misma tabla o de otra.
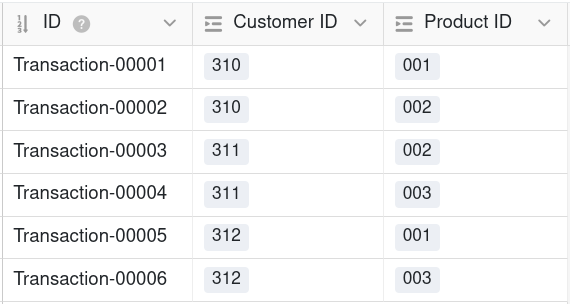
Por consiguiente, una base de datos relacional crea el vínculo entre dos tablas tanto en una relación 1:1 como en una relación 1:n dando a la tabla B las claves primarias de los registros de datos de la tabla A como claves externas. Para una relación n:m, sin embargo, se requiere otra tabla que combine las claves primarias de ambos registros de datos vinculados como claves externas en una fila.
Las propiedades ACID #
Las siguientes propiedades ACID garantizan la integridad de los datos y la fiabilidad de las transacciones en las bases de datos relacionales:
- Atomicidad garantiza que las transacciones se completen o no se ejecuten en absoluto, evitando la pérdida de datos y las transacciones incompletas.
- Consistencia garantiza que las transacciones se adhieren a todas las reglas definidas de la base de datos para que los datos estén disponibles posteriormente de forma correcta.
- Aislamiento (Isolation) garantiza que las transacciones paralelas no se influyan entre sí, sino que permanezcan invisibles para los demás hasta que se completen.
- Durabilidad significa que los datos se guardan permanentemente una vez finalizada una transacción.
Estos principios no sólo reducen los datos erróneos, sino que también minimizan los efectos de los fallos del sistema. Al garantizar que el estado de un sistema de base de datos relacional es coherente en todo momento, se pueden exportar, importar y restaurar datos de forma rápida y sencilla.
Ventajas de las bases de datos relacionales #
Cuando las bases de datos aún estaban en pañales, cada aplicación almacenaba los datos en su propia estructura jerárquica o en red. Estas estructuras de datos eran ineficaces, inflexibles y difíciles de mantener. Sólo el modelo relacional resolvió este problema introduciendo una lógica de base de datos tabular que aún hoy permite almacenar y recuperar datos de forma eficiente.
Otra ventaja de las bases de datos relacionales es su flexibilidad y adaptabilidad al cambio. Es muy fácil añadir, actualizar o eliminar tablas y registros de datos sin tener que revisar toda la estructura de la base de datos. Esto facilita la gestión de grandes cantidades de datos. Además, las tablas ofrecen una visualización intuitiva de los datos y un acceso rápido a los registros de datos vinculados.
Una de las mayores ventajas de un modelo de base de datos relacional es la integridad referencial. Garantiza que cada valor de clave externa existe en relación con la clave primaria correspondiente. Así se evitan las incoherencias en los datos y se garantiza que todas las relaciones entre los registros de datos sean correctas.
Incluso si varios usuarios trabajan con los registros de datos al mismo tiempo, se mantiene la coherencia de los datos. Además, un modelo de base de datos relacional tiene ventajas sobre las bases de datos no relacionales porque la normalización reduce las redundancias y anomalías no deseadas.

SQL en bases de datos relacionales #
El Structured Query Language (SQL) fue desarrollado específicamente para bases de datos relacionales y se ha establecido como un lenguaje de bases de datos ampliamente utilizado. Originalmente se desarrolló a partir de un predecesor llamado SEQUEL (Structured English Query Language), por lo que esta pronunciación sigue siendo común hoy en día. Permite añadir, modificar o eliminar datos en tablas y realizar consultas complejas en bases de datos. Por ello, SQL desempeña un papel fundamental en la administración de bases de datos relacionales.
Diferencias entre bases de datos relacionales y no relacionales #
Las bases de datos no relacionales, también conocidas como bases de datos NoSQL, son un término colectivo para todas las bases de datos que no se basan en un modelo de base de datos relacional. Entre ellas se incluyen, en particular
- bases de datos orientadas a documentos
- bases de datos orientadas a objetos
- bases de datos orientadas a columnas
- Bases de datos gráficas
- Bases de datos clave-valor
Como sus nombres indican, las soluciones NoSQL no almacenan los datos en tablas, sino, por ejemplo, en forma de documentos, objetos, columnas, gráficos o pares clave-valor.
Escalado horizontal frente a vertical #
Una base de datos no relacional está diseñada para procesar datos no estructurados en grandes cantidades (big data) y para escalar horizontalmente, es decir, para distribuir la carga entre distintos servidores. En cambio, una base de datos relacional se escala verticalmente en un único servidor. Esto significa que el rendimiento del servidor (CPU, RAM) debe aumentar para poder procesar big data.

Por este motivo, las bases de datos relacionales suelen tener problemas de rendimiento con aplicaciones que hacen un uso intensivo de datos, como el streaming de vídeo, y no pueden hacer frente bien cuando se producen muchos cambios simultáneamente en grandes cantidades de datos. Sin embargo, una base de datos relacional es ideal para cambios de datos frecuentes pero pequeños o grandes cantidades de datos con cambios poco frecuentes.
Una base de datos no relacional puede gestionar muchos accesos y cambios simultáneos incluso con grandes cantidades de datos. Sin embargo, las arquitecturas NoSQL suelen ofrecer poca seguridad en las transacciones e integridad de los datos, lo que las hace inutilizables para aplicaciones críticas para el negocio, como las transacciones financieras.
He aquí un resumen de las diferencias entre bases de datos relacionales y no relacionales:
| aspecto | base de datos relacional | base de datos no relacional |
|---|---|---|
| Organización de los datos | estructurados en tablas | no estructurados |
| Lenguaje | SQL | diferente (p. ej. YAML) |
| Escalabilidad | vertical | horizontal |
| Seguridad de las transacciones | alta | baja |
| Integridad de los datos | fuerte | débil |
En qué debe fijarse al seleccionar una base de datos #
Si tiene que elegir entre distintos tipos de bases de datos, debe tener en cuenta ciertos factores a la hora de tomar su decisión. Hágase, entre otras, las siguientes preguntas:
- ¿Prefiere almacenar datos estructurados o datos no estructurados (por ejemplo, documentos)?
- ¿Cuáles son sus requisitos en cuanto a integridad de los datos y fiabilidad de la base de datos?
- ¿Cuál es el volumen de datos previsto y qué escalabilidad requiere?
- ¿Necesita una gestión ágil de los datos porque quiere hacer ajustes de forma rápida y flexible o porque varios usuarios necesitan acceder a los datos al mismo tiempo?
- ¿Con qué frecuencia se producirán cambios en los datos y qué conclusiones se pueden sacar sobre el rendimiento necesario de la base de datos?
Uso de bases de datos relacionales en la práctica #
Una base de datos relacional es la herramienta elegida si se quiere garantizar una gestión de datos fiable, precisa y eficaz. Por ello, las bases de datos relacionales suelen utilizarse en la práctica para procesos críticos para la empresa en los que mantener la integridad de los datos es especialmente importante. Por ejemplo, son ideales para procesar
- Transacciones financieras (por ejemplo, pagos)
- Datos de inventario en gestión de almacenes
- Datos de clientes en sistemas CRM
- Datos maestros centrales
Debido a su flexibilidad con rigor simultáneo en la estructura de los datos, las bases de datos relacionales también son adecuadas para muchas otras aplicaciones. Suelen constituir la pieza central de los almacenes de datos .
Ejemplos de sistemas de gestión de bases de datos relacionales (RDBMS) #
Bases de datos clásicas #
Los sistemas de gestión de bases de datos relacionales (RDBMS) más utilizados incluyen MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server e IBM DB2. Cada uno de estos RDBMS tiene sus puntos fuertes y débiles. Qué sistema de base de datos relacional encaja mejor depende en gran medida de los requisitos específicos de su empresa.
Bases de datos sin código #
En los últimos años, también se han establecido en el mercado plataformas sin código como SeaTable, que combinan una interfaz de usuario visual con una base de datos relacional. Esto le permite a usted y a sus empleados crear bases de datos relacionales, aplicaciones y procesos sin conocimientos de programación y utilizarlos sin consultas SQL.
SeaTable – la base de datos relacional sin código para la gestión ágil de datos #
SeaTable es una plataforma de IA sin código que se basa en un modelo de base de datos relacional. Está diseñada para registrar datos estructurados en tablas, pero también puede manejar datos no estructurados (por ejemplo, imágenes, documentos) gracias a una gestión de archivos especial. La gran diferencia con las bases de datos relacionales clásicas es la interfaz de usuario visual, que permite a cualquiera analizar y editar datos y crear bases de datos, flujos de trabajo y aplicaciones sin conocimientos de SQL.
SeaTable ofrece una gran flexibilidad y le ayuda a personalizar, optimizar y automatizar sus procesos. También puede utilizar funciones de IA para que la gestión de sus datos sea aún más eficiente. También tiene la libertad de elegir si desea disfrutar de la conveniencia y escalabilidad de SeaTable Cloud o prefiere instalar SeaTable Server en sus instalaciones para conservar la plena soberanía de los datos . Comience con la versión gratuita y compruébelo usted mismo.
Perspectivas de futuro para las bases de datos relacionales #
El futuro de las bases de datos relacionales estará fuertemente marcado por la cuestión de cómo la inteligencia artificial puede simplificar el manejo de los datos y automatizar las tareas rutinarias. Es bueno que SeaTable haya reconocido los signos de los tiempos y ya haya integrado la automatización de la IA en su base de datos relacional.
Además, las bases de datos relacionales se trasladan cada vez más a la nube porque esta tecnología promete mayor escalabilidad, disponibilidad y rendimiento a la hora de procesar grandes volúmenes de datos.
Por último, pero no por ello menos importante, las bases de datos sin código cobrarán mayor protagonismo, ya que permiten procesar y consultar datos de forma sencilla y rápida sin conocimientos de SQL, amplían la base de usuarios para incluir a los Citizen Developers y pueden adaptarse de forma aún más flexible a los requisitos cambiantes de la gestión ágil de datos.
Preguntas frecuentes sobre bases de datos relacionales #
¿Qué es una base de datos relacional?
¿Qué es SQL?
¿Cuáles son las diferencias entre bases de datos relacionales y no relacionales?
¿Cuáles son las ventajas de las bases de datos relacionales?
¿Qué son las propiedades ACID?